 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
現状把握 では、「どういうデータ?」、「何が起こっている?」、「どういう風に起こっている?」と言ったことを調べます。 この段階で、データサイエンスが役に立ちます。
歩留(良品率)を改善したいなら歩留、生産性を改善したいないなら生産性のデータを詳しく調べます。
行が100行くらい、列が2列くらいまでの表形式のデータがあったとします。
こういうデータの時は、 パレート図 、 ヒストグラム 、 箱ひげ図 、 折れ線グラフ といったものを作って、データをグラフにしてみると、良い現状把握になります。
これよりもデータが大きくなると、データサイエンスのいろいろな技が役立ちます。
行数が非常に多い時は、時間的な変化の仕方を見るために、普通に 折れ線グラフ を作ると、ごちゃごちゃしているだけでよくわからないグラフになったり、 PCの処理が非常に遅くなることがあります。
また、列数が多い時に、ひとつひとつの列を見ていくのは大変です。
「データサイエンス」と言えるかはわかりませんが、データ全体の可視化ができるグラフがあります。
このサイトでは、
Excelによるデータ全体の可視化
、
Rによるデータ全体の可視化
、
Pythonによるデータ全体の可視化
というページで具体的な方法を紹介しています。
また、
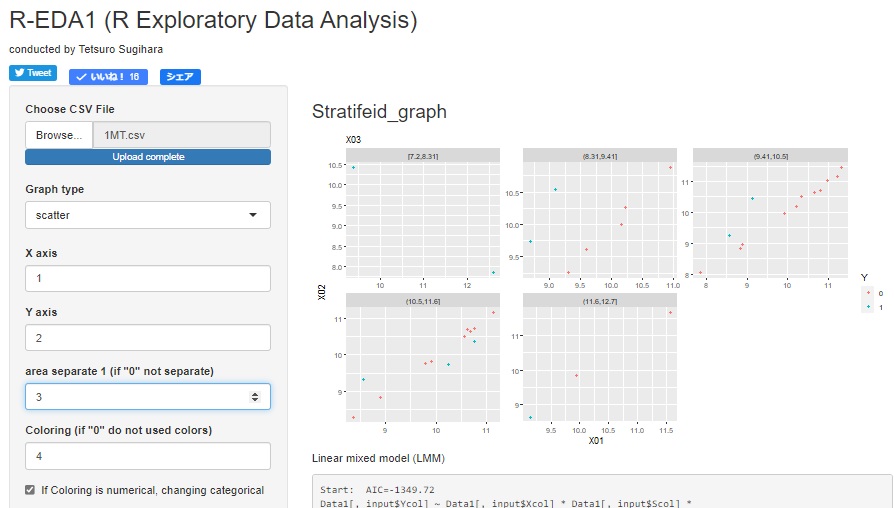
R-EDA1
では、様々なグラフがGUIで簡単で作れるようになっています。
層別のグラフ
も簡単に作れます。
まず、 サンプリング を使ったり、 メタ知識 や 特徴量エンジニアリング の技を駆使して、データの量を減らします。
こうすると、重要な情報があぶり出されて来ることがあります。
このサイトの実施例としては、 Rによる準周期データの分析 や Pythonによる準周期データの分析 のページがあります。
上記の方法は、広い意味での、 時系列解析 です。 データが時間の順に並んでいたり、日時のデータが入っていたりして、時間的な変化を把握することが重要な場合に役に立ちます。
時間的な変化を把握することは、重要ではない時には、 サンプルの類似度の分析 や、 多対多の分析 が役に立つことがあります。
このサイトの実施例としては、 Rによるサンプルの類似度の分析 や Rによる行と列の項目の、項目同士の類似度の分析 のページがあります。
順路
 次は
要因解析のためのデータサイエンス
次は
要因解析のためのデータサイエンス
