 Pythonによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Rによる変数別の折れ線グラフ
Pythonによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Rによる変数別の折れ線グラフ
Pythonによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Rによる変数別の折れ線グラフ
Pythonによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Rによる変数別の折れ線グラフ
変数が複数ある時に、とりあえず全部を見てみるための方法です。 データの並び方が、時系列になっていれば、時系列解析になります。
質的変数はダミー変換して、この方法が使えるようにしています。 1列に3つのカテゴリが入っていれば、3列のデータが作られます。
下記の例では、X1〜X9という変数が量的変数で、X10という変数が質的変数です。
変数別の折れ線グラフは、大きく分けると、1枚のグラフに重ね合わせる方法と、変数別にグラフを作る方法があります、
変数別にグラフを作る方については、下記の方法の場合、変数の数が多いと、グラフを描く時間が相当かかります。
PCによっては、フリーズするかもしれません。
Rでこのグラフをもっと手軽に使う方法を、筆者は見つけていません。
このグラフを使いたいのなら、Pythonにして、
PandasのPlot(matplotlib)
を使ったり、
Excelのスパークライン
を使った方が手軽です。
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
df2.plot()# 層別の折れ線グラフを描く
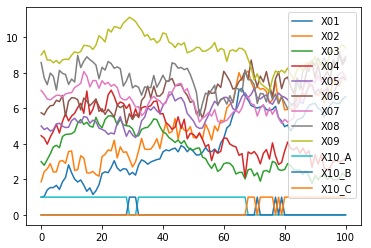
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
df2.plot(subplots=True, sharey=True)# Y軸の範囲を合わせて、折れ線グラフを描く
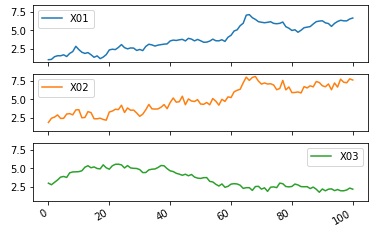
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
df2.plot(subplots=True)# Yの範囲の異なる折れ線グラフを描く
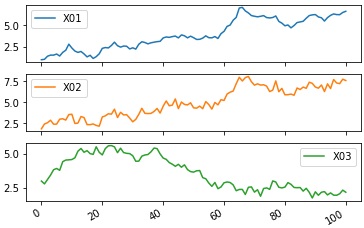
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
import matplotlib.pyplot as plt# パッケージの読み込み
import seaborn as sns # パッケージの読み込み
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
sns.heatmap(df2) # ヒートマップを描く
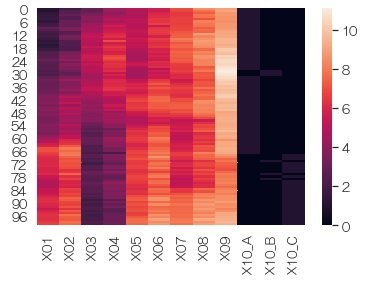
各変数で、平均0、標準偏差1に 標準化 してから、グラフにします。 値が大きく異なる変数が入っている時に、それぞれの変数の様子がよく見えるようになります。
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
import matplotlib.pyplot as plt# パッケージの読み込み
import seaborn as sns # パッケージの読み込み
from sklearn import preprocessing # パッケージの読み込み
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
df3 = preprocessing.scale(df2)# 標準化
sns.heatmap(df3) # ヒートマップを描く
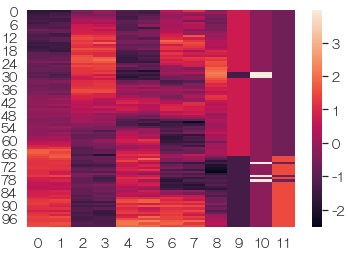
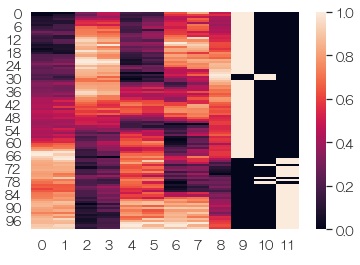
各変数で、最小値0、最大値1に正規化してから、グラフにします。 効果は標準化と似ています。 質的変数が混ざっている場合は、こちらの方が0と1の出方が見やすいです。
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
import matplotlib.pyplot as plt# パッケージの読み込み
import seaborn as sns # パッケージの読み込み
from sklearn import preprocessing # パッケージの読み込み
%matplotlib inline
sns.set(font='HGMaruGothicMPRO') # PandasのPlotのグラフの見た目をseaborn風にする。グラフのフォントを設定する
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data.csv" , engine='python')# データを読み込み
df2 = pd.get_dummies(df)# 質的変数はダミー変換
df3 = preprocessing.minmax_scale(df2)# 正規化
sns.heatmap(df3) # ヒートマップを描く
Plotlyを使うと、一部を拡大して見ることができます。 波形がたくさんあるような時系列データは、データが多いと波形がつぶれてわからなくなりますが、 任意の場所を拡大して見れるので便利です。 また、Plotlyは、動作が非常に軽いのも魅力です。
import os #パッケージの読み込み
import pandas as pd #パッケージの読み込み
import plotly.express as px#パッケージの読み込み
import plotly.io as pio#パッケージの読み込み
os.chdir("C:\\PyTest") # 作業用ディレクトリを変更
df= pd.read_csv("Data2.csv" , engine='python')# データを読み込み
df['X']=df.index # 行番号の列を作る
fig = px.line(x = df['X'], y = df['Y'])# 折れ線グラフのデータを作る(X軸は行番号)
fig.show()# 折れ線グラフを描く
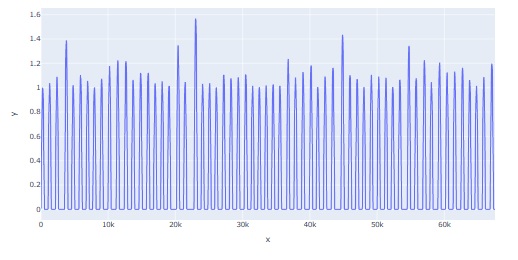
※ この画像は、Jupyter Notebookの画面のコピーなので、拡大縮小はできません。Jupyter Notebookの画面では拡大縮小ができます。
