 Rによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Pythonによる変数別の折れ線グラフ
Rによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Pythonによる変数別の折れ線グラフ
Rによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Pythonによる変数別の折れ線グラフ
Rによるデータ分析 |
Excelによる変数別の折れ線グラフ |
Pythonによる変数別の折れ線グラフ
テーブルデータ全体の可視化 の一種です。
変数が複数ある時に、とりあえず全部を見てみるための方法です。 データの並び方が、時系列になっていれば、時系列解析になります。
質的変数はダミー変換して、この方法が使えるようにしています。 1列に3つのカテゴリが入っていれば、3列のデータが作られます。
下記の例では、X1〜X9という変数が量的変数で、X10という変数が質的変数です。
変数別の折れ線グラフは、大きく分けると、1枚のグラフに重ね合わせる方法と、変数別にグラフを作る方法があります、
変数別にグラフを作る方については、下記の方法の場合、変数の数が多いと、グラフを描く時間が相当かかります。
PCによっては、フリーズするかもしれません。
Rでこのグラフをもっと手軽に使う方法を、筆者は見つけていません。
このグラフを使いたいのなら、Pythonにして、
PandasのPlot(matplotlib)
を使ったり、
Excelのスパークライン
を使った方が手軽です。
library(dummies) # ライブラリを読み込み
library(ggplot2) # ライブラリを読み込み
library(tidyr) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data2 <- dummy.data.frame(Data)# 質的変数はダミー変換
Data2$No <-as.numeric(row.names(Data2)) # 行番号を取得
Data_long <- tidyr::gather(Data2, key="Yno", value = Ys, -No) # 縦型に変換(Noの列以外を積み上げる)
ggplot(Data_long, aes(x=No,y=Ys, colour=Yno)) + geom_line() # 層別の折れ線グラフを描く
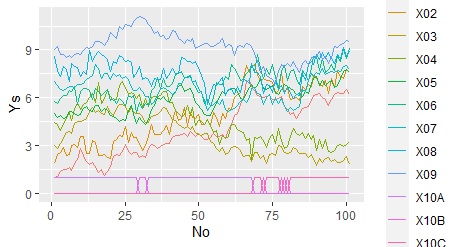
「nrow=1000」というのは、「縦に1000個の枠を作る」という指示で、カテゴリの数よりも多ければ1000でなくても良いです。
library(dummies) # ライブラリを読み込み
library(ggplot2) # ライブラリを読み込み
library(tidyr) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data2 <- dummy.data.frame(Data)# 質的変数はダミー変換
Data2$No <-as.numeric(row.names(Data2)) # 行番号を取得
Data_long <- tidyr::gather(Data2, key="Yno", value = Ys, -No) # 縦型に変換(Noの列以外を積み上げる)
ggplot(Data_long, aes(x=No,y=Ys)) + geom_line() + facet_wrap(~Yno,nrow=1000)# 枠を分けて折れ線グラフを描く
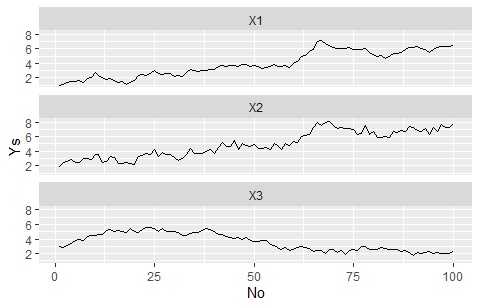
library(dummies) # ライブラリを読み込み
library(ggplot2) # ライブラリを読み込み
library(tidyr) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data2 <- dummy.data.frame(Data)# 質的変数はダミー変換
Data2$No <-as.numeric(row.names(Data2)) # 行番号を取得
Data_long <- tidyr::gather(Data2, key="Yno", value = Ys, -No) # 縦型に変換(Noの列以外を積み上げる)
ggplot(Data_long, aes(x=No,y=Ys)) + geom_line() + facet_wrap(~Yno,scales="free",nrow=1000)# Yの範囲の異なる折れ線グラフを描く
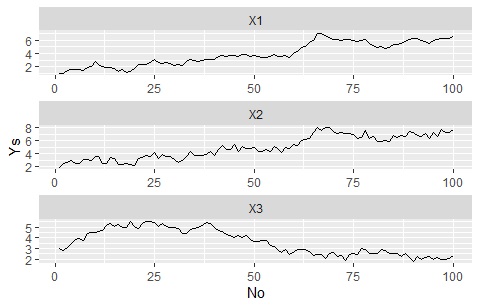
library(dummies) # ライブラリを読み込み
library(ggplot2) # ライブラリを読み込み
library(tidyr) # ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data2 <- dummy.data.frame(Data)# 質的変数はダミー変換
Data2$No <-as.numeric(row.names(Data2)) # 行番号を取得
Data_long <- tidyr::gather(Data2, key="Yno", value = Ys, -No) # 縦型に変換(Noの列以外を積み上げる)
ggplot(Data_long, aes(x=No,y=Ys)) + geom_line() + facet_wrap(~Yno,scales="free")# Yの範囲の異なる折れ線グラフを大量に描く
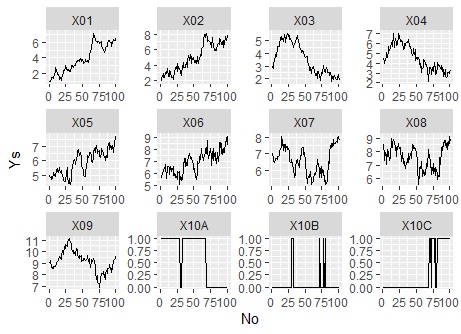
Plotly を使うと、一部を拡大して見ることができます。 波形がたくさんあるような時系列データは、データが多いと波形がつぶれてわからなくなりますが、 任意の場所を拡大して見れるので便利です。 また、Plotlyは、動作が非常に軽いのも魅力です。
library(plotly) # パッケージの読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data$Index <-as.numeric(row.names(Data)) # 行番号を読み込み
plot_ly(Data, x=~Index, y=~Y, type = 'scatter', mode = 'lines') # 折れ線グラフを描く(X軸は行番号)
