 R-EDA1によるデータ分析 | Rによるデータ分析
R-EDA1によるデータ分析 | Rによるデータ分析
R-EDA1によるデータ分析 | Rによるデータ分析
R-EDA1によるデータ分析 | Rによるデータ分析
EDAのページ に、実務向きのEDAの話がありますが、R-EDA1は、そのようなEDAを誰でも手軽にできるように作られたフリーソフトです。
無料で使えます。 ユーザ登録等もありません。
下記のリンクを開くと、ソフトが立ち上がります。
初期設定はなく、初めて立ち上げたら、すぐに使えます。
https://ecodata222.shinyapps.io/R-EDA1/
ソフトは、Rstudio社が提供しているサーバで動くため、アプリのダウンロードやインストール作業はありません。 (「自分のパソコンだと、うまく動かない!」ということがないです。) OSにも依存しません。 例えば、スマホでも使えます。
ソフトから、データの入っているcsvファイルを開いて、やりたい分析を選ぶだけです。 Rを使っているソフトですが、Rのコードを自分が書く必要はないです。
データ分析の解説書には、回帰分析、主成分分析、といった手法が説明されています。 実務では、それらの手法に加えて、質的変数を量的変数にする処理や、出力のグラフ作成を組合せていきます。 このソフトは、よく使われる組合せごとに、まとめています。
レストランで、「麺類」のページを選んでから、「鍋焼きうどん」を選ぶ感覚で使えるようにしようとしています。 一般的な、データ分析の解説書の内容は、 「うどんの作り方」、「出汁の取り方」、といった内容ですので、やりたいことに行き着くまでに時間がかかります。
数週間、数か月といった時間をかけても良いのなら、じっくり分析プランとコードの作成を進めても良いかもしれませんが、 R-EDA1は、 緊急事態対応の打合せをしている時に、その打合せの中で分析結果を出したいような場合も想定しています。
データ分析の解説では、「教師あり学習・教師なし学習」、「目的変数が量的変数・質的変数」、といった観点で手法を分類するのが一般的です。
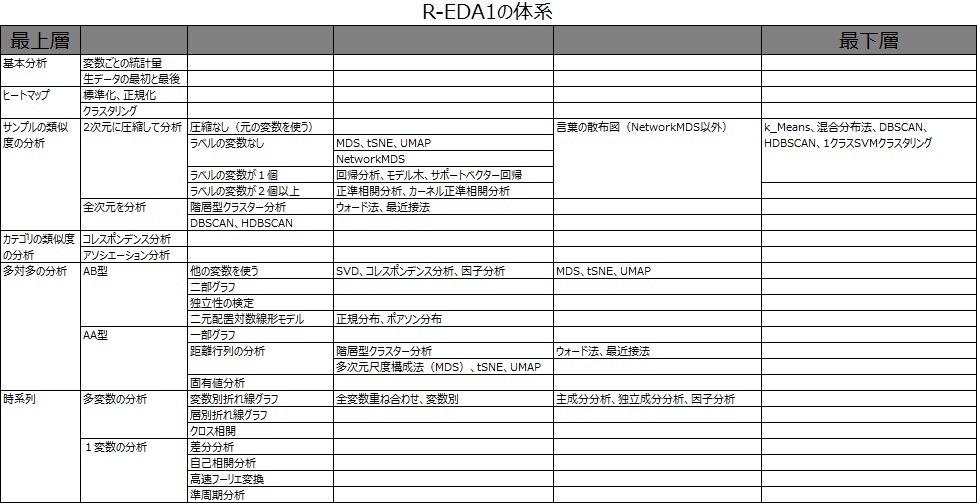
R-EDA1の手法は、EDAのレシピ集なので、「回帰分析」、「主成分分析」といった個別の素材を単独で選ぶようにはなっていません。 ほとんどが、前処理、複数のモデルの組合せ、グラフをセットにしたレシピになっています。
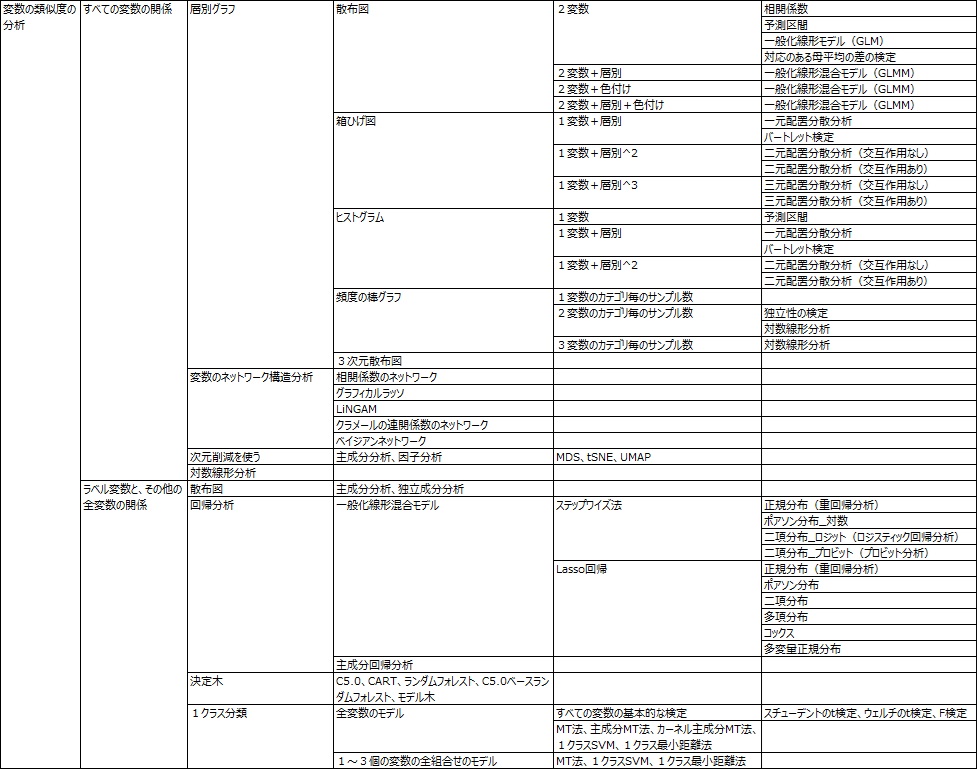
表形式のデータの見方で、分類しています。
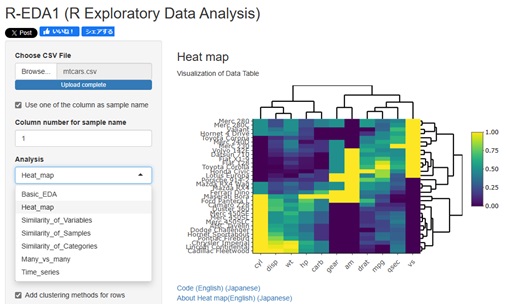
大きな分類としては、「基本統計量」、「ヒートマップ」、
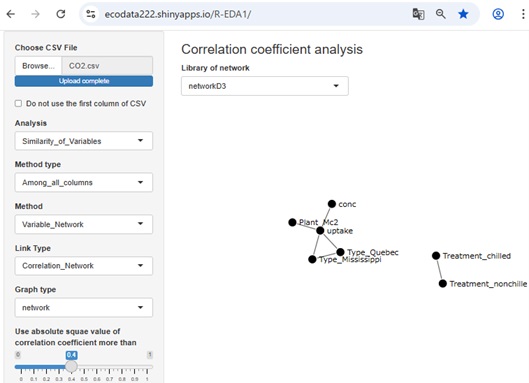
「列の項目の類似度を見る」、「行の項目の類似度を見る」、「行と列の項目の類似度を見る」、「時系列(データの順番)で見る」の6つです。
「カテゴリの類似度」は、「列の項目の類似度」の応用技です。
「時系列で見る」は、「列の項目の類似度を見る」に「行の項目を見る」が入っています。
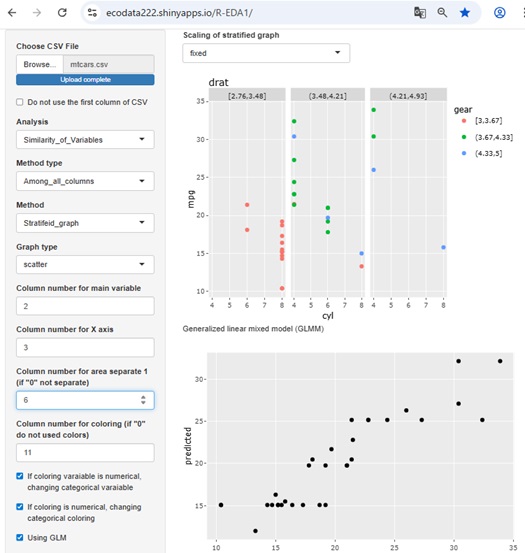
細かい話になりますが、このアプリでは、量的変数を前提とした手法を使う時は、質的変数は、 ダミー変換 をして、量的変数として使えるようにしています。 反対に、質的変数を前提とした手法を使う時は、量的変数は、 1次元クラスタリング をして、質的変数として使えるようにしています。 (このアプリのデフォルトでは、数値の範囲を5分割して、それぞれをカテゴリにします。)
この変換によって、量的変数と質的変数が混ざっていても、分析できるようになっています。 また、その手法がもともと前提としたタイプではないデータを扱うと、分析できることが増えます。 例えば、量的変数を前提とした手法は、量的変数の非線形の関係を扱うのが苦手ですが、 質的変数を前提とした手法を使うと、非線形の関係も分析できるようになります。
Rguiも、RStudioも、特に設定しなくても、日本語(ひらがな、カタカナ、漢字)が使えるソフトです。 ところが、Rを含んでいるコードをウェブアプリにする、Shinyというライブラリは日本語が扱えません。 コードの中に日本語が含まれているとエラーになります。 また、入力データの中に日本語が含まれていてもエラーになることがあります。
csvファイルの文字コードがANSIだと、読み込まれません。 Shift_JISだと、読み込みはできます。
Shift_JISに変換するには、EXCELの場合、「CSV Shift_JIS(コンマ区切り」で保存します。
csvファイルはメモ帳で開いて、Shift_JISで保存することもできます。
ただ、Shift_JISにしても、手法によってはエラーが出て動かないことがあります。 また、全角の記号で表示が元と違うこともあります。 これを避けたい場合は、ローマ字でも良いので、英数字のデータにしておく必要があります。
操作画面は、日本語版がありません。
ただ、最近のブラウザには翻訳機能がありますので、それを使うと、ある程度は日本語で読めるようになります。
下の例は、Google Chromeですが、Microsoft Edgeでも同じような感じになります。
専門用語の翻訳がおかしいことがあるので、この訳語をそのまま使わない方が良いです。
例えば、「寸法縮小」となることがありますが、「次元削減」が一般的な訳語です。
R-EDA1の本体は、RStudio社が提供している無料サーバにあります。 基本的に計算時間は、このサーバの能力で決まっています。
Rなどにあるサンプルデータ(irisなど)の規模なら、計算時間が気になることはないと思いますが、 数秒くらい待つことがあります。 データがあまり大きいと、計算が止まることがあるかもしれません。 データが大きいと、データの通信時間もそれなりにかかります。
Rstudioが自分のPCにインストールされていれば、
「自分のPCで動かす」ということもできます。
以下の2行をRstudioのConsoleに入力すると、R-EDA1が起動します。
なお、自分のPCで動かす場合、R-EDA1で使うライブラリで、インストールされていないものがあれば、エラーが出ます。
エラーメッセージの中に、どのライブラリがないのかが書かれています。ないものはインストールが必要です。
最初は、ライブラリでないものが複数あるかと思いますので、「エラー → インストール」の作業の繰り返しになるかと思います。
library(shiny)
runUrl( "https://data-science.tokyo/R-EDA1.zip")
上のコードでエラーが出る場合は、下記を試してください。
下記の場合は、Rのホームディレクトリに、ui.Rとserver.Rが解凍されます。
ui.Rとserver.Rのいずれかを、RStudioで開くと、R-EDA1が使えるようになります。
download.file("https://data-science.tokyo/R-EDA1.zip", "R-EDA1.zip", mode = "wb")
unzip("R-EDA1.zip", exdir = "R-EDA1")
GitHubにコードを置いていますので、コードをダウンロードして使うこともできます。
ui.Rとserver.Rのどちらかを、Rstudioで読み込むと起動します。
https://github.com/ecodata22/R-EDA1
※ ダウンロードをしないで、GitHubのコードで起動する方法がShinyではできるはずなのですが、なぜか筆者の場合はできません。
また、筆者は試したことがないですが、AWSなどのクラウドでShinyを使うこともできるそうです。 自前で用意する必要がありますが、これを立ち上げて、R-EDA1のファイルを置けば、リッチな計算環境で計算することもできるようです。
入力データは、csvファイルだけです。 Excelで、保存する時に「csv」を選ぶと、作ることができます。
また、細かいことはソフト自体に書いていますが、データの形がソフトが想定しているものと違うと、 エラーになったり、異常に計算時間がかかったりします。 例えば、量的変数の中に、質的なデータが混ざっていると、「質的変数」と判断され、膨大な数のカテゴリのある質的変数になるため、計算時間が異常に長くなります。
使い方の詳しい説明は、ソフトの画面にありますし、さらに詳しい説明のリンクも、その中にあります。
具体的な実施例は、 R-EDA1によるデータ分析 にあります。
更新履歴は、 R-EDA1のリリースノート にあります。
