 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
テキストマイニングは、文章の解析方法です。 小説、解説記事、報告書、アンケートの自由記述文など、を解析します。 「テキスト」というデータならではの特徴があります。
テキストマイニングは データマイニング のひとつの分野として扱われる事もあります。
テキストマイニングの初歩は、
形態素解析
で、テキストを単語単位にばらばらにして、
Aを元のテキスト、Bをそのテキストに含まれる単語にした
A-B型(行列の分解)
のデータを作り、分析に入って行く方法があります。
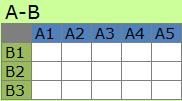
これだけでも ネットワークのグラフ を使って 共起 の関係を見たり、 多変量データの傾向解析 を使って、単語の使用量の変化を見たり等、いろいろなアプローチがあります。
ただし、このアプローチは、 人が文章を読んで、意味を理解するのとは違っていますので、最初は何をしているのかがわかりにくいと思います。
人と会話できる 人工知能 や、文章を解析するシステムなどがありますが、 自動作文 のような技術を使っている訳ではなく、 テキストの単位をうまく調整して、 共起の分析をうまく使っているものが、けっこうあるようです。
テキストマイニングは、 その分野の素人が、未知の分野の文章について、「どんな話をしているのだろう?」、と言った事を把握するのには、大変威力があります。
筆者の知る限りですが、 そのテキストの詳しい内容は知らないけれども、どんな内容かは知っている人にとっては、 一般的な解説書にあるようなテキストマイニングでは、あまり面白い結果は出てこない事が多いようです。
こういった話は、テキストマイニングだけでなく、データ解析全般であります。 テキストマイニングでは、特に顕著に表れて来るような感じがしています。
質的研究は、 質的社会調査 の中で使われる方法です。 質的研究とテキストマイニングの共通点として、テキストデータを分析する点があります。 異なる点として、質的研究では、単語単位でばらばらにしません。
質的研究は、テキストを理解、要約、まとめ、という分析をします。 分析者が全部読まなければならない上に、分析者の分析能力にも高いものが求められますが、テキストマイニングではできないことができます。
「ソーシャルメディアの経済物理学 ウェブから読み解く人間行動」 高安美佐子 編著 日本評論社 2012
ネットワーク
上(大量のブログ)の単語の量の変化の分析が中心です。
形態素解析
の後の単語を分析します。
流行語ができる過程や、日常語のゆらぎを時系列分析や、確率伝播のモデルを検討しています。
経済指数を、ネットの言語情報から作る研究は、広告の効果測定や、社会的な大流行の予測の技術として、研究が進んでいるそうです。
「テキストデータの統計科学入門」 金明哲 著 岩波書店 2009
テキストデータに形態素解析をしたりする点は異なりますが、
何らかの数値データになると、
多変量解析
や
データマイニング
の手法の出番になっています。
その部分を主に解説しています。
共起を指標にした
ネットワーク分析
、時間を目的変数にして単語を説明変数にした
重回帰分析
による
時系列解析などが面白かったです。
「ビッグデータを活かす技術戦略としてのテキストマイニング」 菰田文男、那須川哲哉 編著 中央経済社 2014
組織の知識を扱う方法としてテキストマイニングを論じています。
テキストマイニングを主軸にした技術経営の研究事例が8つ紹介されています。
「特許情報のテキストマイニング 技術経営のパラダイム転換」 豊田裕貴・菰田文男 編著 ミネルヴァ書房 2011
特許情報が代表的ですが、技術開発などの情報を得るためにテキストマイニングをする場合、
重要な情報は、頻度の低い単語に含まれていると考えています。
ところが、こうしたロングテールの部分の分析には、
多変量解析
は適さない点を指摘しています。
解決策として提案されているのは、共起や係り受けなどによる単語のセットの探索と深堀りと、様々なテキストの探索です。
NMFによる関連度の解析や、
Q分析による構造の解析もあります。
この本では、年毎の変化を時系列分析として、よくしているのですが、
データの数値自体を見たり、年の違いで
層別する事が、分析の方法になっています。
「Excelで学ぶテキストマイニング入門」 林俊克 著 オーム社 2002
Excelをベースにして、具体的にテキストマイニングを解説しています。
「自然言語処理の基礎」 吉村賢治 著 サイエンス社 2000
「自然言語処理の基礎」 奥村学 著 コロナ社 2010
両者とも、形態素解析、構文解析、意味解析、文脈解析の構成になっています。
文章を分解して、論理学的に分析しているのですが、筆者は目的がよくわからないでいます。
「修理伝票のデータマイニング :市場品質管理の効率化」 堀聡 著 計測と制御 計測自動制御学会 2002
バスケット分析(アソシエーション分析)で、品質問題の候補の予兆を発見する話です。
この分析方法は、雑多なアプトプットが大量に出るところが、扱いの難しいところですが、
この記事では、属性の優先度を利用して、意味のある情報だけを抽出できるようにしたのが、ポイントのようです。
順路
 次は
形態素解析
次は
形態素解析
