 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
テキストマイニング では、 形態素解析 の後に、単語の関係や使われ方を調べる進め方が、よく解説されています。
一方、作者を見分ける分析ように、 判別問題 として、進める事もできます。 また、 サンプルの類似度の分析 として、「複数のテキストを分類する」という進め方もあります。
テキストを比較する場合、一般的には、 それぞれのテキストを読んで、意味や言葉の使い方を調べます。
テキストマイニング としてテキストを比較する場合は、 そのテキストは、いろいろな単語の出現回数や、 どういった単語が 共起 しているのか、という事で特徴付けられます。
テキストマイニングのソフト には、こういった情報を、csvファイルで表として出力する機能があります。 表の行がテキストの違いを表していて、表の列が単語になっています。 つまり、テキストがサンプル、単語が変数、という形のデータです。
例えば、
データサイエンス
のページのテキストを、句点(「。」)を単位として、
形態素解析
して出力すると、冒頭の部分の出力は、図のようになります。
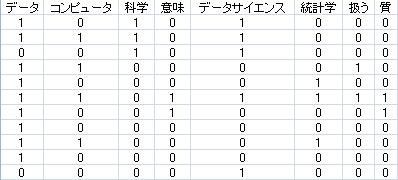
この行列の各行は、ひとつの文です。
ちなみに、この表は、同じ文の中にその単語が使われていれば、「1」と各形式です。 同じ単語が何度も使われている時に、その回数を書く形式もあります。 解析でわかる事は変わって来ます。 単純に共起の関係を見たい場合は、0-1の形式がシンプルで扱いやすいです。
テキスト単位の分析では、目的変数(Y)に相当する変数を作って、 判別問題の分析 として進めたり、 サンプルの類似度の分析 として、サンプルの関係(表の行の関係)を調べます。
サンプルの類似度の分析をテキストデータでするのは、 「定量的、客観的な 親和図 」と言えるかもしれません。
テキストマイニングの難しさに「意味」の扱い方があります。
人がテキストを直接読むときは、単語の意味を理解しながら読み進み、 テキスト全体の内容を理解しますが、 テキストマイニングでは、このアプローチをしません。
ただ、人の読み方と同じではないものの、その単語の周辺の単語を見れば、 その単語に込めた「意味」が読みとれます。 このようにして、単語の表記そのものの奥にあるものを解析する分析は、 「潜在意味解析」と呼ばれています。
潜在意味解析は、もともとは、表の行がテキストの違いを表していて、表の列が単語になっているデータから、 文字通り「意味」を解析する方法として考えられたようです。 トピックモデル と呼ばれています。 現在は、行や、列の項目を違うものにする事によって、テキストマイニング以外の分野でも使われています。
共起 のところで、テキストの単位が変わると結果が変わる事を書きましたが、 テキストを比較する場合も、この点が重要になります。
文とは、句点「。」ごとのまとまりの事です。 テキストマイニングで扱うテキストの最小単位は、文になります。
Excelには、ひとつのセルに入っているデータに対して、「区切り文字」で別々のセルに分割する機能があります。 一般的に区切り文字としては、「スペース」、「,」、「タブ」が使われますが、 「。」も設定できます。
この機能を使うと、長いテキストを文ごとに分割できます。 実際に、この機能を使う場合は、分割された文を、ソフトの入力ファイルになるように加工する必要があります。 数が多い場合は、マクロを作ると良いです。
ここまで特に触れませんでしたが、「 テキストマイニング 」では、単語レベルでテキストを解析する事が主流になっています。
人がテキストを分析する時は、テキストを最初から読んで、「を」や「が」、といった単語も手掛かりにして、 そのテキストを分析していきます。 しかし、テキストマイニングの主流のやり方は、こういった事をしません。 形態素分析のソフトは、テキストを単語に分解する時に、文法的な知識を使っていますが、 解析者は、いったん単語に分解されたものから分析をスタートしますので、 「単語の集まり」という目で、テキストを見ています。
テキストデータの使い道は、 自動翻訳や、機械との会話などを思い浮かべてしまいますが、これをするには、テキストを機械的に作る 自動作文 の技術も必要になります。
その技術を使わずに、 単語の集まりとしてテキストを見るだけでも、さまざまな分析や応用ができるのが、テキストマイニングの面白さ、と思います。 「テキストデータが何かに化けるための、ブラックボックス」と思っても良いかもしれません。 ただ、この使い道は、日常的にはないものですので、面白さを伝えたり、もっと深めていくのが難しいところです。
「主成分分析の基本と活用」 内田治 著 日科技連 2013
主成分分析
を使って、単語の近さを調べる分析や、テキストの近さを調べる分析があります。
「データマイニング入門 :Rで学ぶ最新データ解析」 豊田秀樹 編著 東京図書 2008
ひとつの章が潜在意味解析になっています。
約20ページで、潜在意味解析の概要を学び、Rで実際に実施してみるところまで、できるようになっています。
順路
 次は
量質混合データの分析
次は
量質混合データの分析
