 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
このページのタイトルの「量質混合データ」というのは、量的変数と質的変数が混ざっているデータセットのことです。 一般的な名前がないようなので、このサイトではこの名前にしました。
量質混合データになる時のポイントは、2つあります。
ひとつは、目的変数が量的変数、説明変数が質的変数の場合です。 また、これの逆の場合もあります。
もうひとつは、説明変数の中に、量的変数と質的変数が混ざっている場合です。 目的変数と説明変数の区別がなく、量的変数と質的変数が混ざっている場合もあります。 例えば、工場のデータだと、長さなどを測定した値が量的変数、測定した装置の名前が質的変数になっている場合があります。
量質混合データの汎用的な扱い方としては、 量的データを質的データに変換 して、質的データの方法を使うか、 質的データを量的データに変換 して、量的データの方法を使うかの、どちらかです。
質的変数だけになると、定量的な分析としては粗くなりますが、非線形を簡単に扱える利点があります。
量的変数だけになると、数式で扱いやすくなる点が良いのですが、一般的な量的変数だけの時よりもわかりにくい分析になります。 例えば、カテゴリの相関分析があります。
決定木 では、目的変数が量的な場合と、質的な場合で名前が違いますが、自動で区別してくれるソフトもあります。
手法にもよりますが、一般的な決定木は、 となり、量的データは、区間を表す質的データとして扱います。
モデル木 は例外で、局所的な回帰分析をします。
量質混合の潜在変数モデル は、似ている変数やカテゴリのグルーピングを潜在変数でできるので、自分で結果を整理しないとグルーピングできない他の手法よりも便利です。
全体的な回帰分析はできるのですが、局所的な回帰分析はできないので、局所的に数値的な関係が重要な時は対応しきれないです。
量質混合の潜在変数モデルの分析例です。
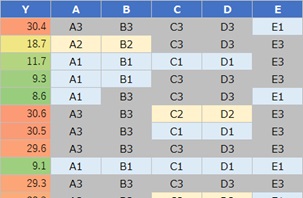
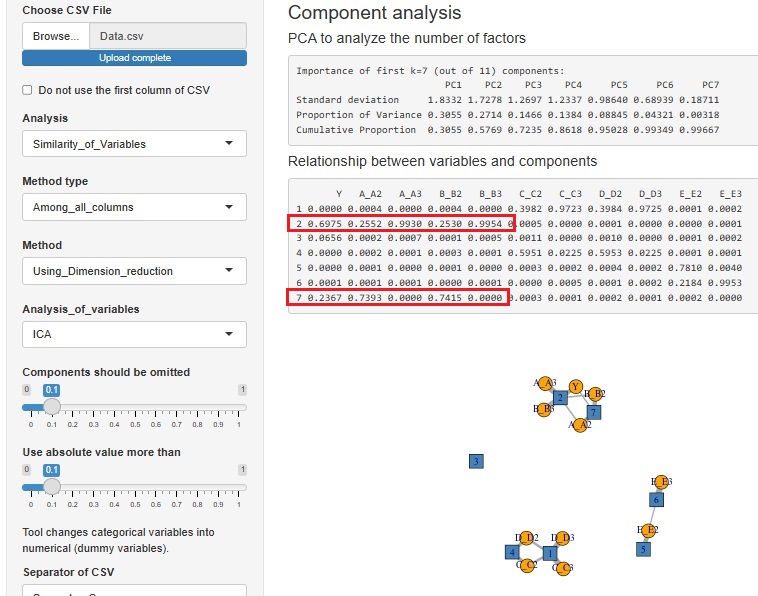
ひとつは、目的変数Yが量的変数で、説明変数が質的変数の場合です。
Yが、AとBで決まっていることがわかります。
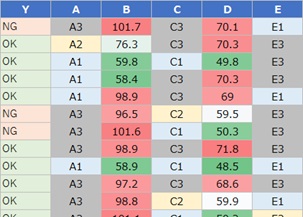
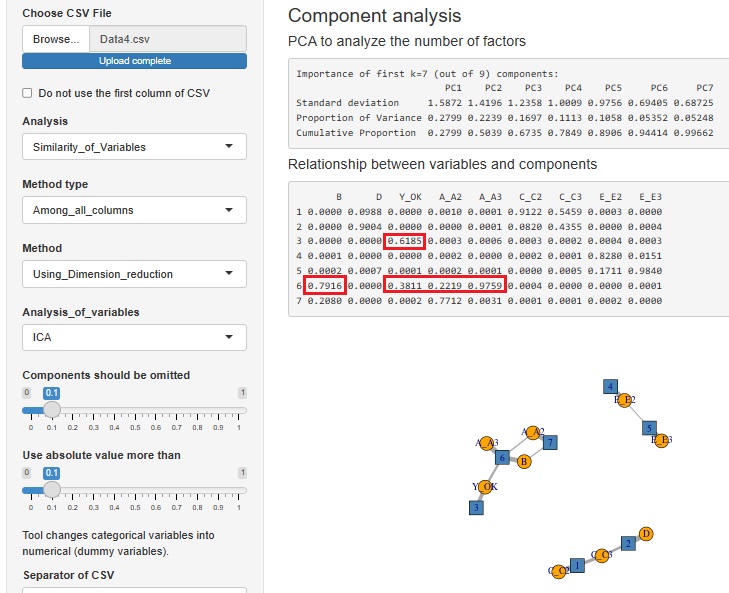
もうひとつは、目的変数Yが質的変数(OK・NG)で、説明変数が量質混合の場合です。
Yは、A、Bと共通の潜在変数で説明できるものの、説明変数から説明できない何かがあることが6割(0.6185)あることがわかります。
順路
 次は
グラフ統計
次は
グラフ統計
