 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
経時解析 のデータは、例えば、変数が7つの場合でもごちゃごちゃして来ます。
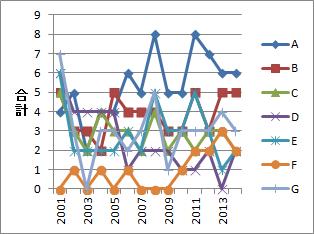
変数ごとにグラフを分ければ、わかりやすくなりますが、 7つならまだしも、もっと変数が増えたら、現実的な方法ではないです。 アソシエーション分析 や テキストマイニング のデータの解析の場合は、変数の数が膨大になる事がよくあるので、これらのデータに対して、 0-1データの時系列解析 をしたい時にも困ったことになります。
ところで、ビジネスの場では、「右肩上がり」のグラフかどうかが、よく注目されます。 売上のグラフが右肩上がりでしたら、「売上が増えている」という意味ですので、好ましい状態です。
このように、時系列のグラフでは、「上昇傾向なのか」、「下降傾向なのか」、「あまり変わらないのか」、 という事がざっくりわかるだけでも、重要な情報になることがあります。
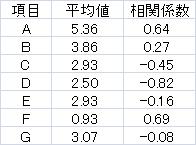
ざっくりとした傾向を調べるために、相関係数を使います。 「年」や「月」をXとして、時系列データとの相関係数を計算します。
相関性 は、普通、静的なデータの関係性を調べることに使いますので、特殊な使い方です。
時系列のグラフを折れ線グラフで作ることが多いですが、このグラフを散布図のように眺め、 「上昇傾向は、相関係数がプラス」、「下降傾向は、相関係数がマイナス」、「あまり変わらなければ、相関係数は0に近い」、 と解釈してしまいます。
「年」で集計する場合、年の数字を使って、相関係数を計算するのでも、問題はないです。
しかし、「月」で集計する場合、例えば、2007年12月を「200712」という数字で集計したとすると、 この数字は、年をまたいだところで、各月が均等にならないので、問題があります。
こうした場合、「200712」といった数字は使わない方が良いです。 例えば、200701を「1」として、200801を「13」というようにして、 「何カ月目」を表す数字を作って、その数字との相関係数を計算する方が良いと思います。
単純に傾向だけを調べたいのなら、相関係数だけで良いです。
しかし、例えば、「傾向はあまり変わらない」だとしても、「ずっと発生し続けていることが変わらない」と、 「ほとんど発生していない事が変わらない」では、意味がだいぶ違います。
この違いを出すのに、平均値も計算します。
相関係数と平均値を計算すると、データはとてもシンプルになります。 グラフも一目でそれぞれの変数の傾向がわかり、注目した方が良い変数を見つけやすくなります。 グラフの例は、ExcelとRの2通りを作りました。
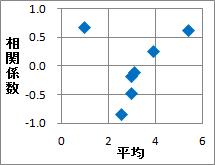
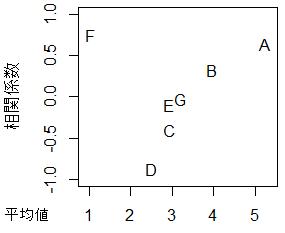
このグラフでは、Y軸が傾向の方向と強さを表します。
X軸は平均の値をそのままにしていますが、 テキストマイニング のデータなどでは、変数毎に平均値がケタ違いに違ったりしますので、 平均の対数をとったものをX軸にした方が良い事もあります。
Excelは、変数の名前をグラフに書きこむ事ができないようです。 Rの場合は、 言葉の散布図 に作り方をまとめました。
このサイトを テキストマイニング した例です。
「環境と品質のためのデータサイエンス」をテーマにしているサイトですが、 「環境」と「品質」に関する更新が減っている事がわかります。 また、頻度がそんなに多くないものの、「原因」という言葉の使用が増えている事もわかります。
ちなみに、一般的なテキストマイニングは、発生頻度の多い単語に目が行きがちなのですが、 この解析では、グラフの左側が発生頻度の少ない単語になっていて、頻度が少なくても調べられるようにしてあります。
また、一般的なテキストマイニングで、時間的な傾向を見ることはないのですが、 この方法は傾向を見ています。 記録や、報告の解析方法に向いています。

変数が大量な場合、 平均値や相関係数を機械的に計算することになりますが、 これらの集計値は、 外れ値の影響を受けやすいものでもあります。
そのため、これらの集計値を使う時は、あくまでざっくりとした計算として使っている事に注意が必要です。
このページのデータは サンプルファイル にあります。
順路
 次は
スモールデータで傾向解析
次は
スモールデータで傾向解析
