 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
通常の
散布図
でプロットがある場所に、言葉が書かれている散布図があります。
「言葉の散布図」と、ここでは呼ぶ事にします。
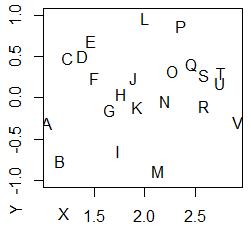
主成分分析、 多次元尺度構成法、 自己組織化マップ、 多変量データの傾向解析では、解析結果は言葉の散布図でまとめると、とてもわかりやすいです。
そのデータをどうやって計算したのかが、手法によって違いますが、 言葉の散布図に使われているデータの形式は、どれも同じで、項目の質的データと、縦軸、横軸の2つの量的データがあります。 このページの例の散布図のデータは、 サンプルファイルになります。
1次元で表している絵は、印象が弱い事があります。
3次元で表している絵は、一般的には、とてもわかりにくいです。 設計等のソフトでは、物は3次元の構造をしているので、3次元で表現できるようになっていますが、 回転させたりしなければいけないです。
パッと見て、一番わかりやすいグラフは、2次元の絵と思います。 実際、 多変量解析 や データマイニング の手法に、2次元の絵を解析結果にする手法が多いのは、これが理由と思います。
言葉の散布図の場合、 言葉の数が数百の規模を超えて来ると、文字が重なったりして、実用的でなくなって来ます。 しかし、この規模までなら、パッと見ただけでデータの全容を把握できます。
縦軸と横軸を何にするのかが、解析者の腕の見せ所です。
Rを使った言葉の散布図の作り方は、 ggplot2 のページにまとめています。
ちなみに、このサイトでは、最初、Rのmaptoolsというライブラリを使ったグラフの描き方を紹介していて、 このサイトの中には、このライブラリで作った言葉の散布図もあります。 後でわかったのですが、ggplot2を使った方が簡単ですし、値を散らす機能も使えるので便利です。
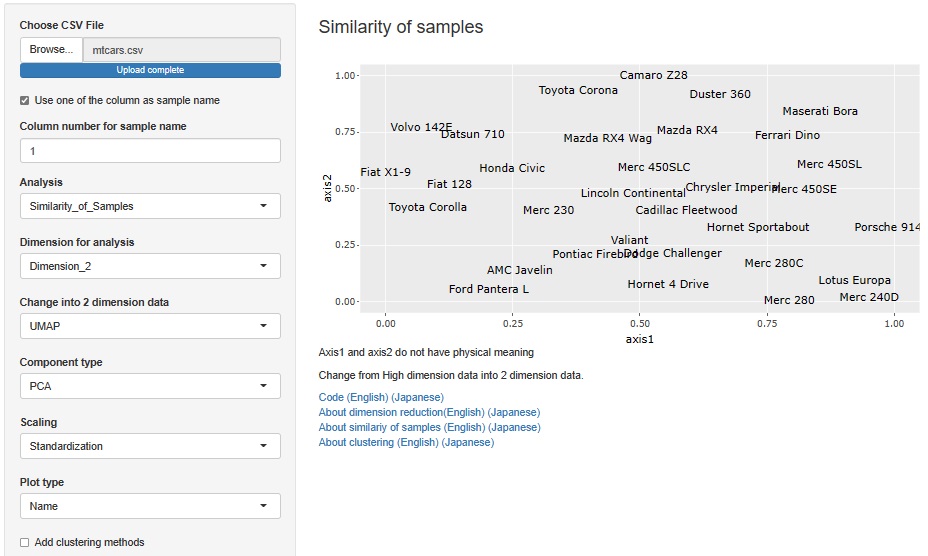
R-EDA1 では、手軽に作れるようになっています。
下の分析例は、
mtcars
のページにあります。
順路
 次は
対応のあるデータの散布図
次は
対応のあるデータの散布図
