 R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1
R-EDA1によるデータ分析 |
ウェブアプリR-EDA1mtcarsは、自動車の特徴のデータです。 各自動車について、11種類の評価が数値で表されています。
このページでは、「このデータはどうなっているのか?」、「このデータから、どんなことがわかるのか?」という見方で、 R-EDA1 で分析をした事例になります。
R-EDA1は万能ではないので、EXCELも併用する方針にしています。
筆者は、下記のコードでデータを入手して、csvファイルにしています。
Cドライブ直下のRtestというフォルダに保存します。
write.csv(mtcars, row.names = TRUE, "C:/Rtest/mtcars.csv")
mtcars.csv のリンク先で、このサイト内に保存したcsvファイルをダウンロードできます。 なお、保存されているファイルは、「mtcars.csv」なのですが、「mtcars.xls」というファイルとしてダウンロードされ、 「拡張子がおかしい」という意味のエラーメッセージが出る現象があります。 ダウンロードされたファイルの拡張子を「xls」から「csv」に変更すれば、問題なく使えるようになります。
ここからは、任意の場所にある「mtcars.csv」というファイルを使っています。
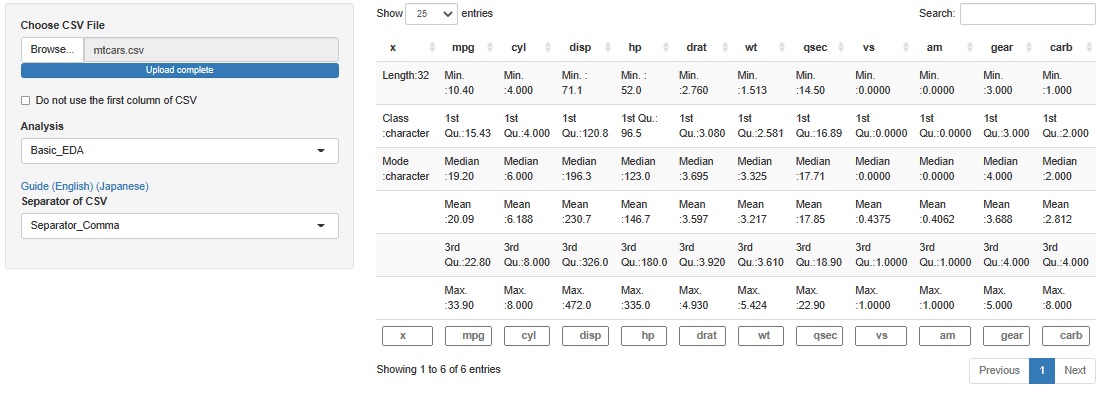
欠損値はないことが確認できます。
参考文献の https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/mtcars.html を日本語にすると、以下になります。
mpg、disp、hp、qsecは性能(実力)を表す数字です。
cyl、drat、wt、vs、am、gear、carbは、設計した構造を表していて、性能の原因になる変数です。 ただし、これらの中にも因果関係があります。
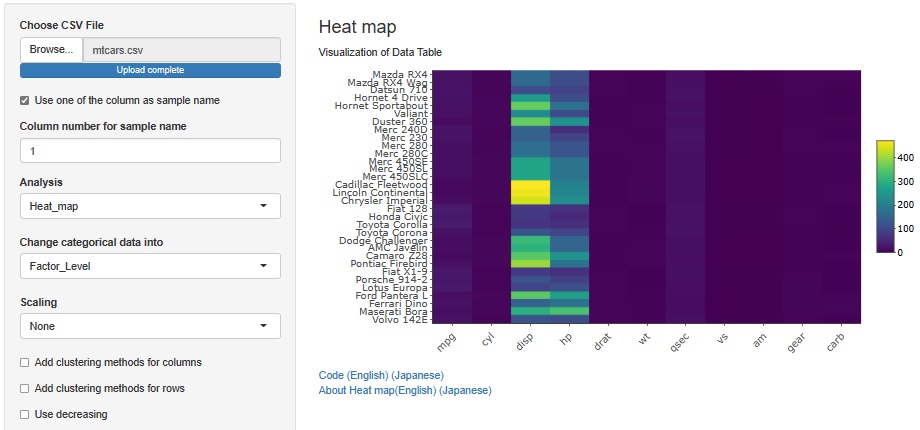
値が大きい変数が2種類あることがわかります。
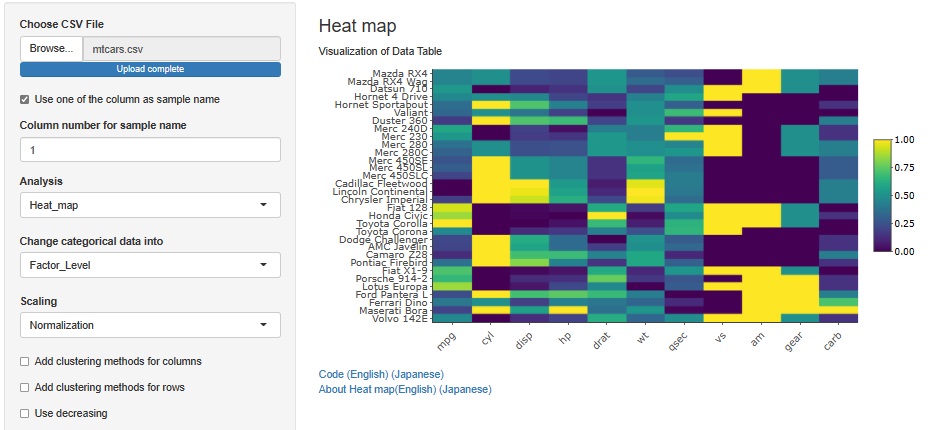
Normalizationをすると、vsとamは、色が2種類しかないので、2水準のデータ(2値データ)なことがわかります。
また、cylとgearは値が色が3種類しかないので、3水準のデータなことがわかります。
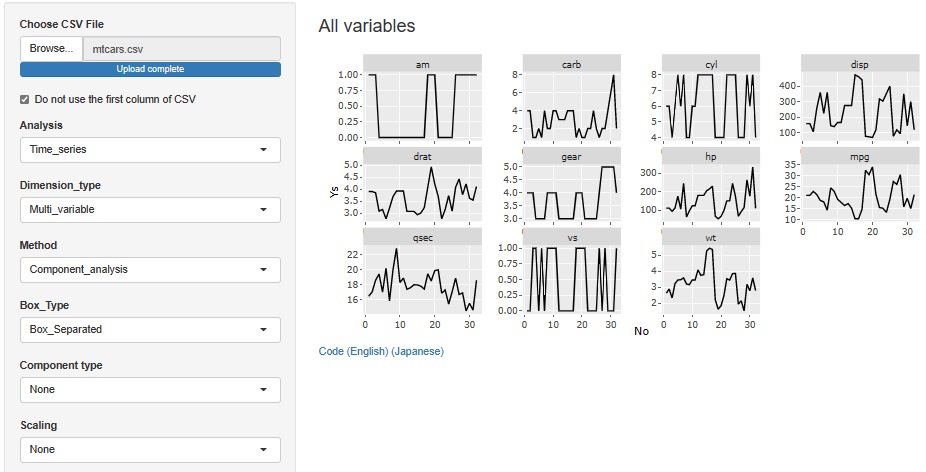
cylは、4、6、8の偶数が3種類あって3水準になっていることがわかります。 gearは、3、4、5の3種類があることがわかります。
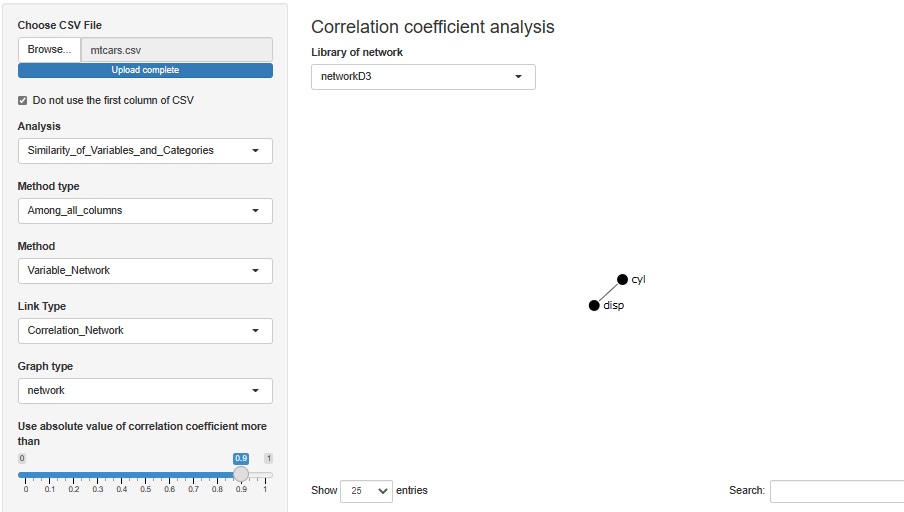
相関係数0.9で、cylとdispがつながります。 排気量がシリンダーの数で、だいたい決まっているということになりますが、その通りかと思います。
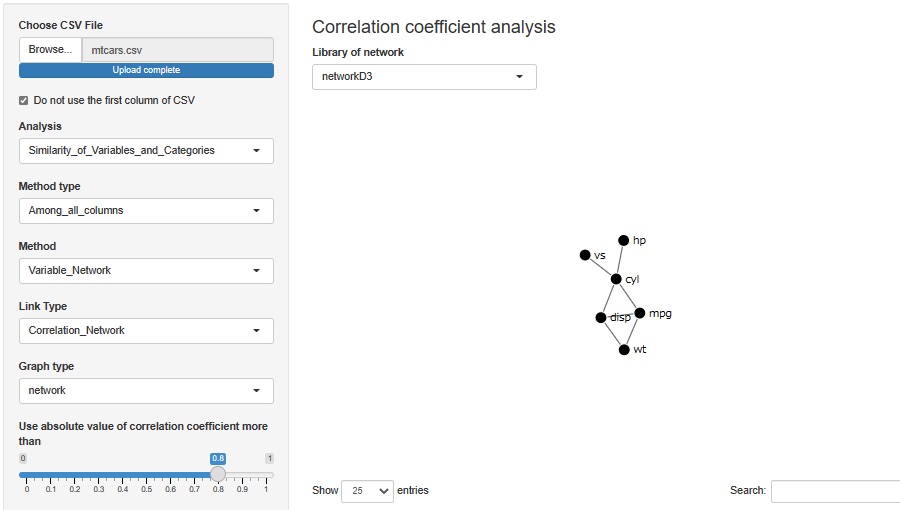
相関係数0.8で、hp、vsがそれぞれ、cylにつながります。 シリンダーの数で馬力が変わる、シリンダーの数でシリンダーの並び方が変わる、ということになります。 また、mpgがcyl、disp、wtと関係があるということも、その通りかと思います。
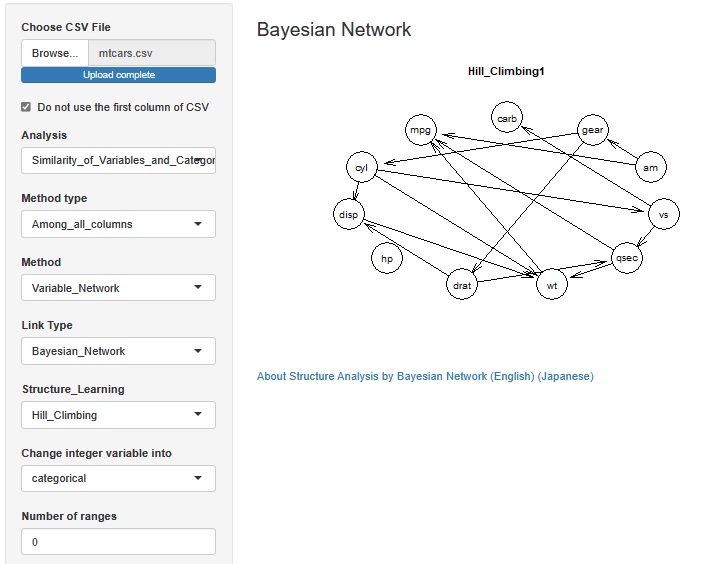
相関関係の分析の一種ですが、 ベイジアンネットワークによるデータの構造解析 をしてみます。
cyl、amといった整数値になっている変数は質的変数として扱うように設定したところ、 質的変数間や量的変数間で矢印が引かれ、質的変数と量的変数では、質的変数から量的変数に矢印が引かれました。 想像している因果関係と、矢印がだいたい合っているようです。
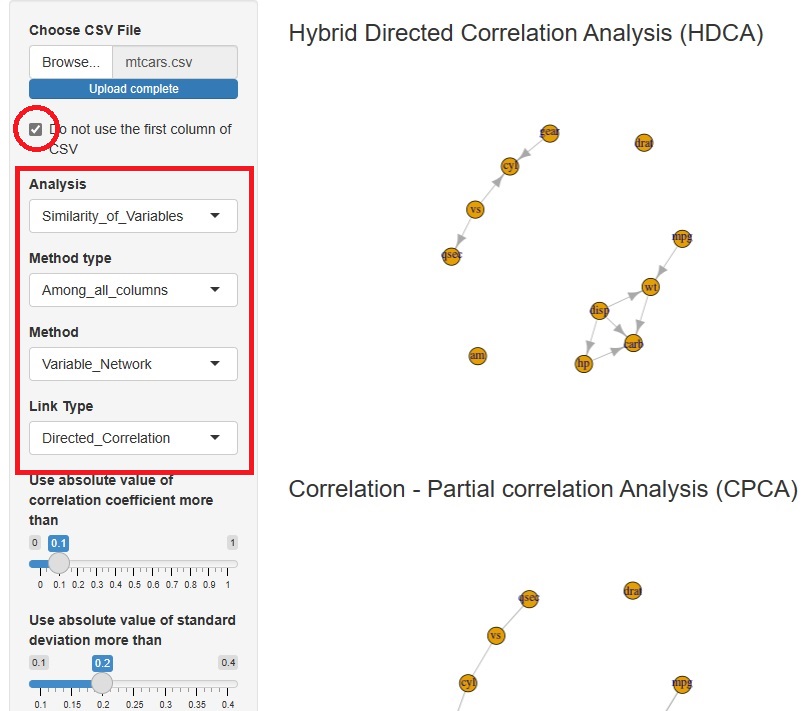
相関関係の分析の一種ですが、 ハイブリッド有向相関分析 をしてみます。
もっともらしい構造を表しているようです。
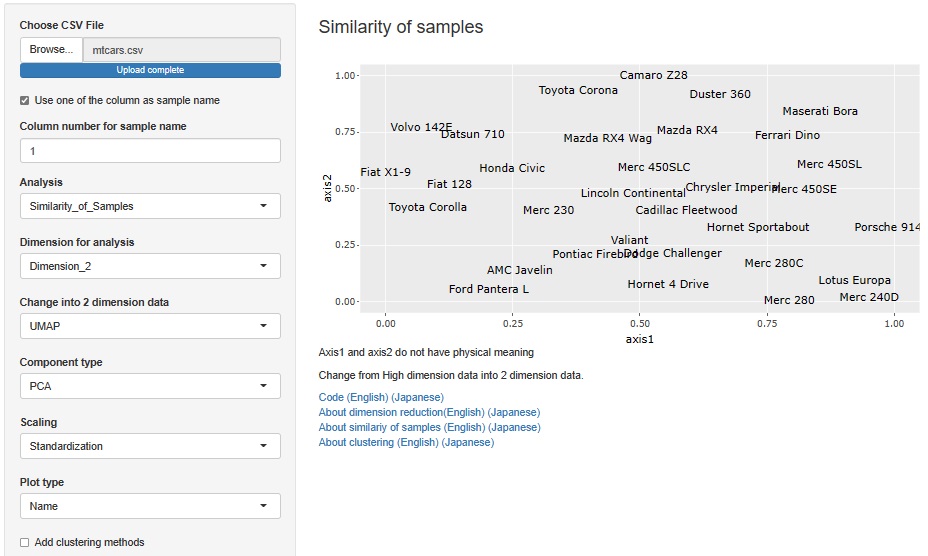
総合的に見て、近いもの同士を調べる分析です。
前処理を何もしないと、値の幅の大きいdispやhpの影響を強く受けますが、それを期待している訳ではないので、PCAを適用することにします。 さらに、それぞれの主成分の影響を平等に評価したいので、Standardizationも適用することにします。
名前の似ているものが近くになっているので、良さそうな配置ができているようです。
性能を表すmpg、disp、hp、qsecだけで、近いもの同士を調べる分析です。
ここから下の分析では、mpg、disp、hp、qsec以外の変数を削除して、「mtcars2.csv」というファイルを作ってから分析しています。
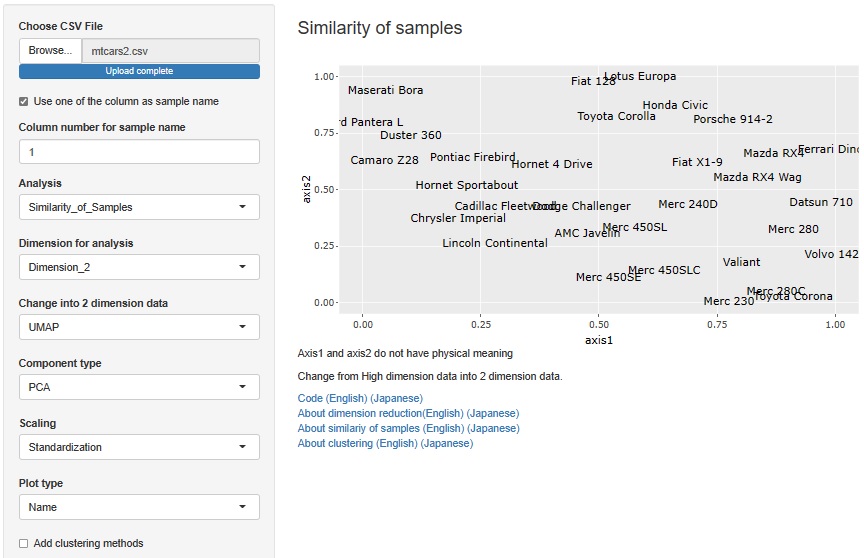
前処理を何もしないと、値の幅の大きいdispやhpの影響を強く受けますが、それを期待している訳ではないので、PCAを適用することにします。 さらに、それぞれの主成分の影響を平等に評価したいので、Standardizationも適用することにします。
名前の似ているものが近くになっているので、良さそうな配置ができているようです。
環境問題対応という点では、mpg(燃費)は重要な指標です。 mpgを良くしようとすると、他の指標にどのように影響があるのかを見てみます。
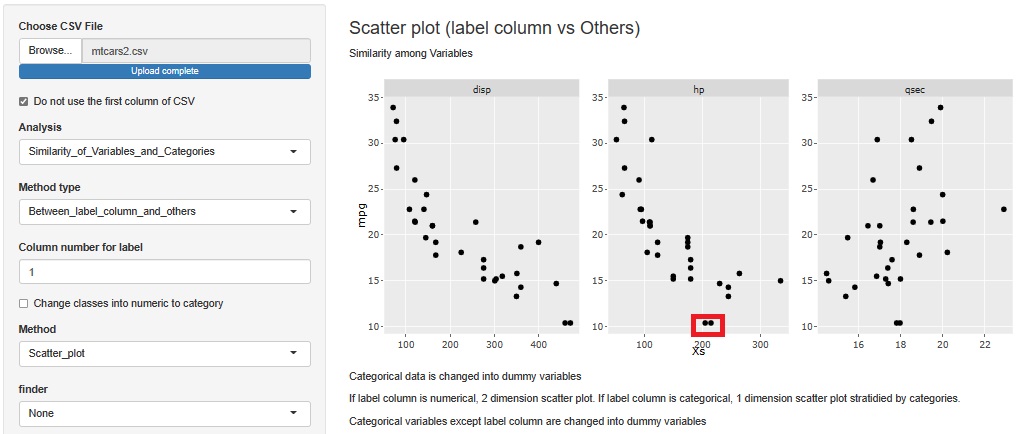
mpgを縦軸にしていて、他の変数が横軸になっています。
まず、mpgとdisp(排気量)は、反比例の関係があることがわかります。 燃費が良くなると、排気量も減るというのは、環境負荷を減らすという点で2つの指標が両立するということになります。
mpgとhp(馬力)も、反比例の関係があることがわかります。 馬力を得ようとすると、燃費が悪くなるということになります。 ただし、hpが100くらいのサンプルだけを見ると、mpgは18から30くらいの幅があります。 また、mpgが15くらいのサンプルだけを見ると、hpは150から320くらいの幅があります。 この幅ができる理由を分析すると、mpgとhpの良さを両立することができるのかもしれません。
mpgとqsecは、特に関係がないようです。 つまり、qsecはある程度高く、燃費も良い車というのは作れることがわかります。
mpgとhpを両立させるための設計条件を検討してみます。
そこで、mpgとhpをかけ合わせた「mpg*hp」という変数を作り、
データから、disp、qsecは削除します。
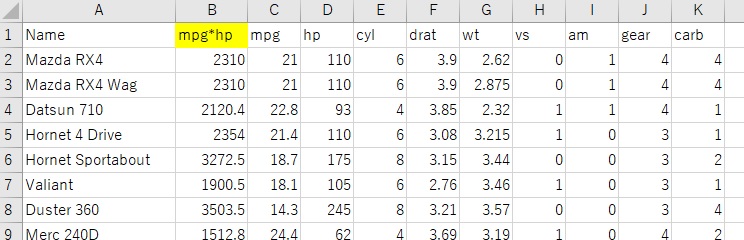
横軸をhp、縦軸をmpgにして、mpg*hpの値で色分けをすると、mpg*hpが高いサンプルは、反比例の曲線の右上側なことがわかります。
どちらかというと、hpが高めでmpgが低めのサンプルがmpg*hpの高い傾向があり、
hpが低めでmpgが高めのサンプルでmpg*hpが高いのは1個だけなので、mpgが高いことよりもhpが高いことが重視された指標になっています。
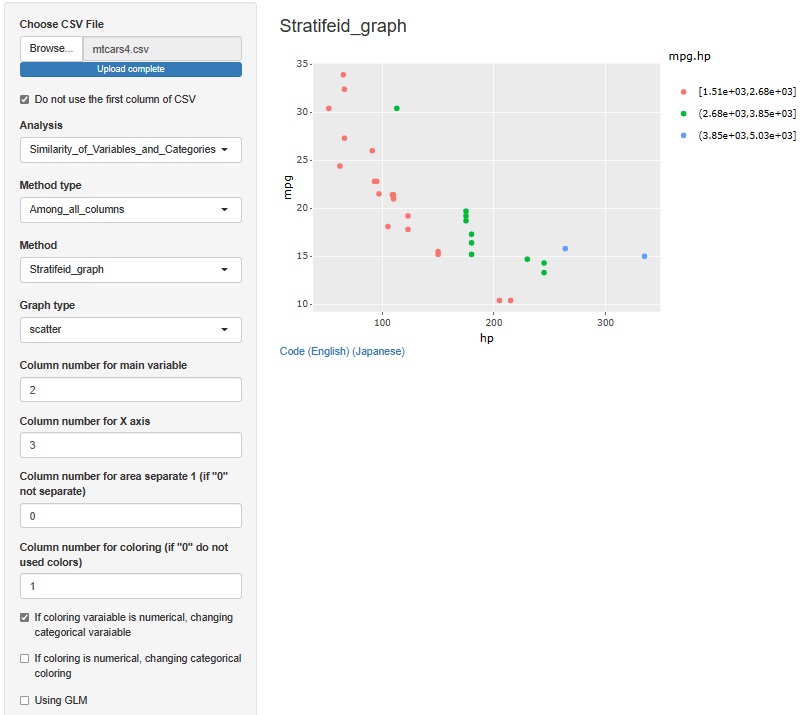
そこで、hpとmpgのそれぞれを
正規化
してから、かけ合わせることにします。
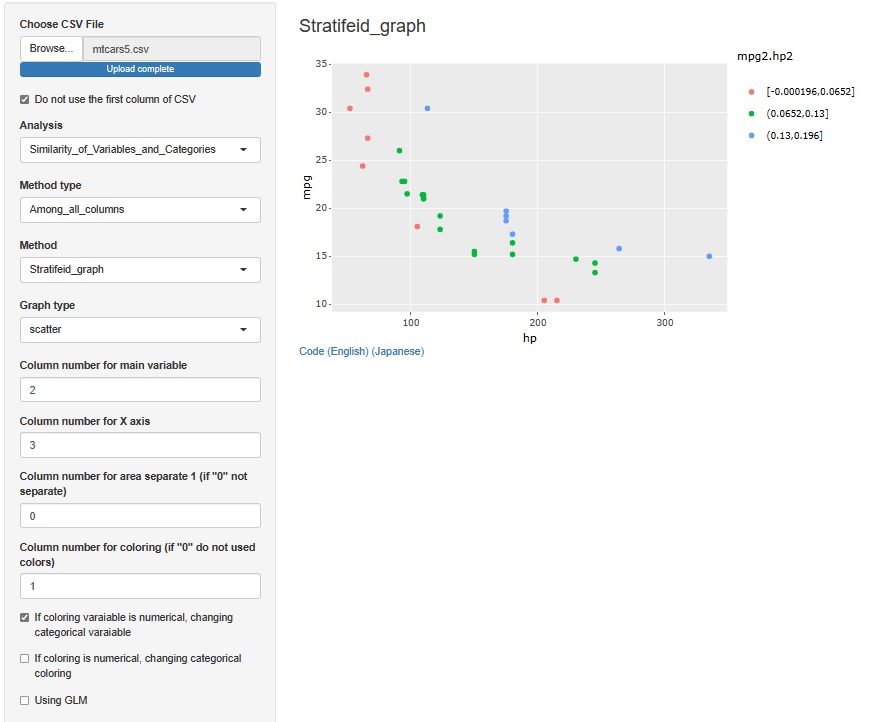
すると、今度はバランスが良さそうなので、この指標を使っていくことにします。
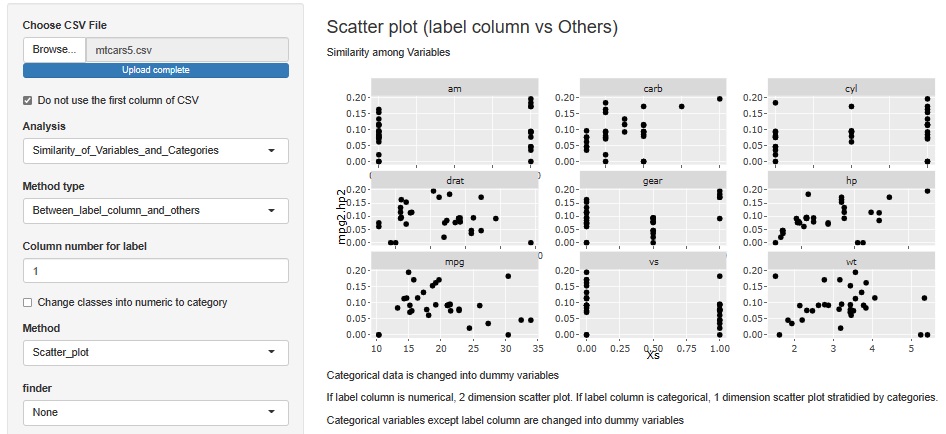
mpg2*hp2を縦軸にして、他の変数を横軸にした散布図です。 「vsが0だと、つまり、V型の方がmpg2*hp2は高い」ということが言えそうです。 mpgとhpを両立させる設計は、これが重要なようです。
その他の変数については、これだけでは結論を出しにくい感じです。 gearは、真ん中の4が一番悪そうに見えるのは、性質としては面白いですが、なぜなのでしょう。。。
R Documentation
mtcarsのデータの詳しい説明があります。
https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/mtcars.html
