
上図のようなデータの場合、
外れ値
が1個あるのは、グラフから簡単にわかります。
外れ値の特徴は、 「大多数の分布から離れている」、 「ある範囲の外」、 「密度の薄いところにある」という風に表現できます。
機械的に外れ値を判定する仕組みを作るには、これらの特徴を使います。
検定 の考え方を使います。 正規分布 と仮定し、 標準化 してしまえば、「3以上は外れ値とみなす」、と言った感じで判定することもできて、簡単です。
「判定したいデータ以外のデータの最大値と最小値の範囲に入るか」、と言った感じで判定するのが簡単です。
現実の問題では、ある値を基準(しきい値)にして、それを超えた時を「外れ値」のように考える事もあります。
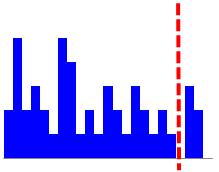
外れ値の特徴として、3つ挙げましたが、下図のようにある値を境にして、
外れ値かどうかが決めている場合は、「ある範囲の外」しか、特徴が当てはまりません。
一般的な統計学では扱わない話なので、いくつか例を並べてみます。
LOF が有名です。
上記の場合、1つの変数の場合でした。 「1つの変数の値が外れているか?」ではなく、「サンプルが外れているか?」を調べたい場合、複数の変数のセットについて判定する事があります。 変数が1つの時よりも、難しくなります。 とはいえ、考え方は同じです。
主成分分析 や、 MT法 で変数を要約してから、変数が1つの時の方法を使います。
主成分分析やMT法を使う事もできますが、 One-Class SVM もあります。 One-Class SVMだと、複雑な形の範囲でも、判定できる場合があります。
LOFは多変量でも使えます。
例えば、主成分分析を使う時ですが、 判定したいデータと参照データが混ざったデータに対して主成分分析をする方法と、 参照データで主成分分析をしてモデルを作ってから、そのモデルを判定したいデータに適用していく方法の2つがあります。
前者の方が手間は少ないですが、外れ値にロバストではない手法を使う場合は、前者の方法はうまくいかない可能性があります。 前者を使う場合は、判定したいデータを複数混ぜずに、1つずつにした方が良いです。
後者の場合は、教師なし学習の方法を予測に使う話になるのですが、馴染みのない方法なので、下記にまとめます。
教師なし学習 でよく知られているのは、 サンプルの仲間分けの分析 に使われるものと思います。 中間層を使った解析 で中間層を作るものもあります。
判定したいデータと参照データを分ける使い道は、これらとはまた別の使い道になります。
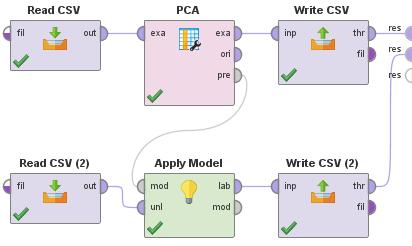
外れ値の判定のために、判定したいデータと参照データを分ける使い方は、基本的に 予測のためのソフトの使い方 と同じです。 主成分分析 の場合は、下図のようにして主成分を取り出した後に、 主成分毎の分析や、 One-Class MT法 の入力データとして使う、などに進めます。
下記のRapidMinerとRの使用例は、やっている事が基本的に同じです。
R の使用例は下記になります。 (下記は、コピーペーストで、そのまま使えます。 この例では、Cドライブの「Rtest」というフォルダに、 「Data1.csv」という名前で学習データがあり、 「Data2.csv」という名前でテストデータが入っている事を想定しています。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data1 <- read.table("Data1.csv", header=T, sep=",") # 学習データを読み込み
Data2 <- read.table("Data2.csv", header=T, sep=",") # テストデータを読み込み
pc <- prcomp(Data1, scale=TRUE) # 学習データを主成分分析
pc1 <- predict(pc, Data1)[,1:3] # 学習データの主成分を第3位まで作成
pc2 <- predict(pc, Data2)[,1:3] # テストデータの主成分を第3位まで作成(学習データのモデルを使うのがポイント)
write.csv(MD1, file = "pc1.csv") # 学習データの主成分をファイルに出力
write.csv(MD2, file = "pc2.csv") # テストデータの主成分をファイルに出力
順路
 次は
異常値の判定
次は
異常値の判定

