 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
One-Class SVMは、 サポートベクターマシン(SVM) の一種ですが、使い方がかなり違います。
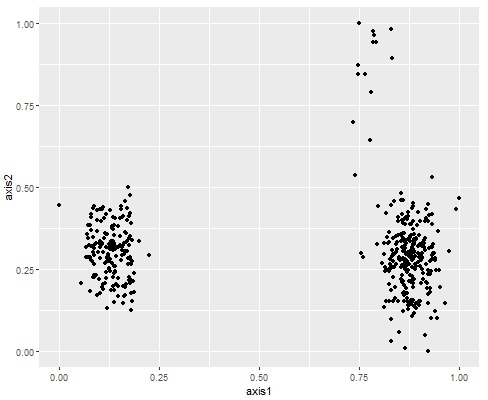
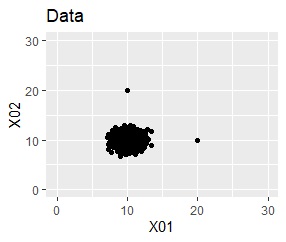
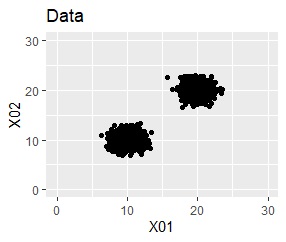
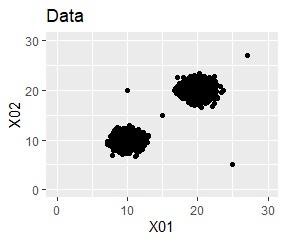
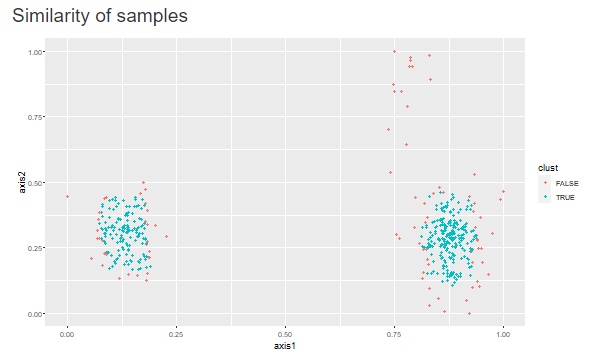
上の図のようなデータがあったとします。
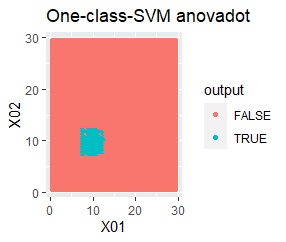
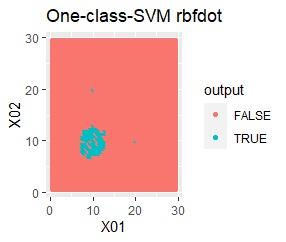
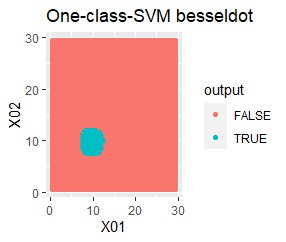
これを、One-Class SVMに入力すると、出力は下の図になります。
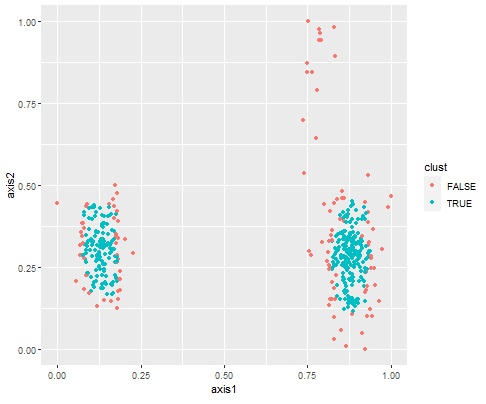
元のデータを、「TRUE」と「FALSE」という分類に分けてくれました。
このTRUEとFALSEは、データの塊の内側と外側になっています。
一般的に知られているSVMは、Y(教師データ)を与えて、Xをどのように区切るとYがうまく分かれるのかを分析しますが、 One-Class SVMは、Yを使いません。 教師なし学習 です。 One-Class SVMは、分類の結果を出力します。
上の例は、2つの塊の外側と内側をうまく分類してくれたケースです。
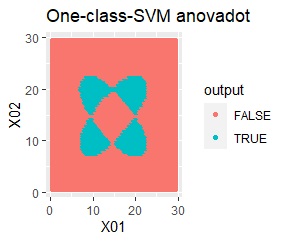
実際にこの手法を使う時は、カーネル関数の選択が大事になります。
例えば、選択が良くないと、下図のような分類になります。
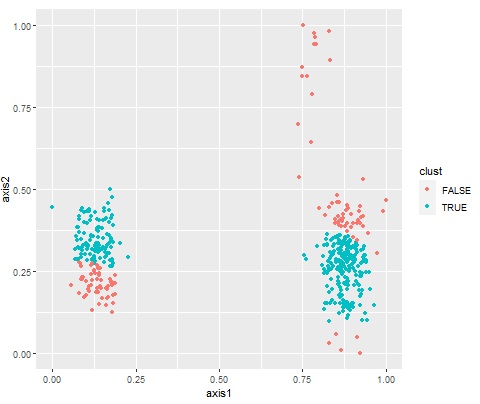
クラスター分析 のk-Means方でkを設定する時と同じ難しさなのですが、 2次元データなら、グラフを確認することで、パラメータの調整ができるのですが、3次元以上になると、この方法が使えません。
R-EDA1 では、3次元以上の場合は、外側と定義したいデータが「外側」と判定されるかどうかで、結果の正しさを確認する方法を使っています。
例えば、3つの塊のそれぞれの中心付近なら安全な事がわかっていて、 それらの位置から離れている時は、警戒する必要がある場合、 分類が未知のデータがあって「外側」に相当するのなら、警戒すべき状況な事がわかります。
この性質を使うと、 異常検知 の方法として使えます。
ウェブアプリR-EDA1 では、上記のk-Means法などは、次元圧縮して2次元データに変換したデータに対して、グループ分けをする方法として使っています。
One-Class SVMもこのような目的の方法として、このソフトには入れています。 一般的なクラスター分析は、データの塊をグループ分けしますが、One-Class SVMを使うと、塊の内側か外側かでグループ分けしてくれるので、 一般的なクラスター分析ではできないグループ分けができます。
この用途の他の方法との比較は、 外れたサンプルの探索 にあります。
Rのkernlabのライブラリの場合、カーネル関数は8種類あります。
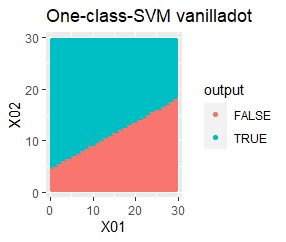
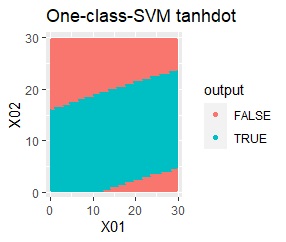
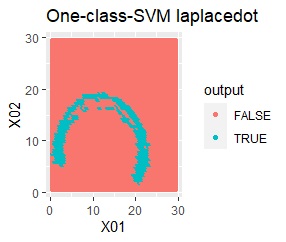
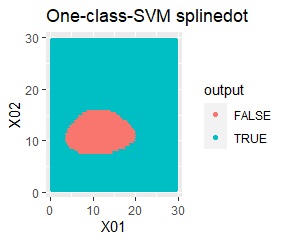
2変数(2次元)のデータについて、データの違いに対して、手法の違いがどのように表れるのかをまとめています。 nuは0.01にしています。
データからモデルと作り、平面を細かい格子にして、それぞれの格子の判定を見ています。 元のデータがある場所の近辺がTRUEで、それ以外がFALSEになるのが理想です。
結論を先に書くと、以下になります。
One class SVMへの期待は、 MT法 では扱えない複雑な分布への対応なのですが、One class SVMも万能という訳にも行かないようです。
2次元正規分布のデータです。
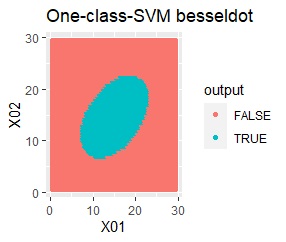
良さそうな判定ができたのは、besseldotだけでした。
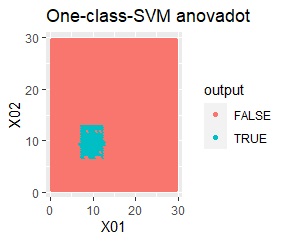
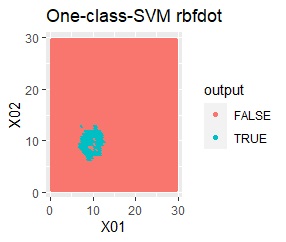
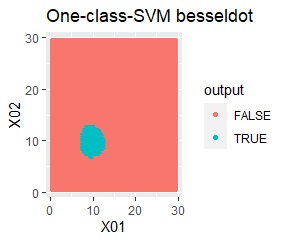
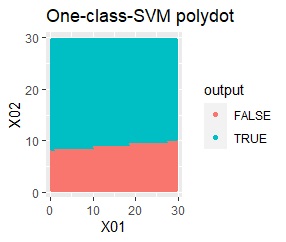
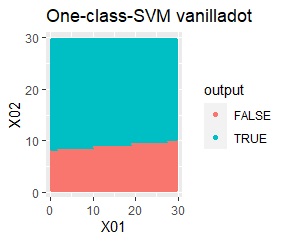
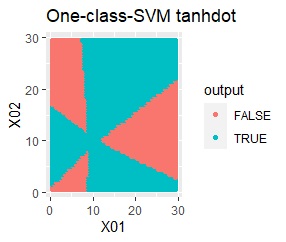
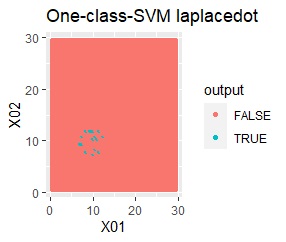
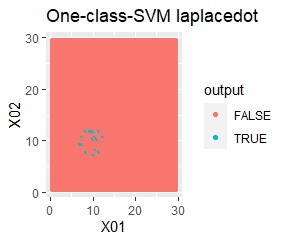
例1Aとほぼ同じですが、外れ値が2つあります。
besseldotは外れ値には影響されていないことがわかります。
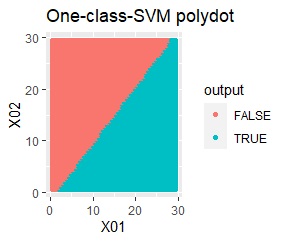
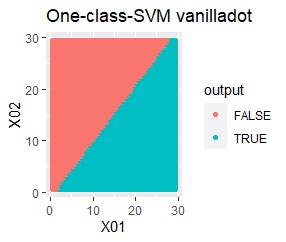
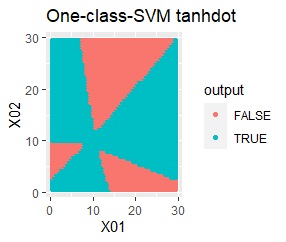
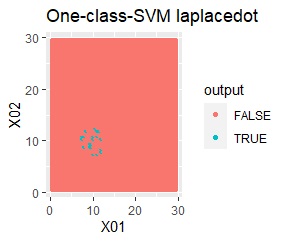
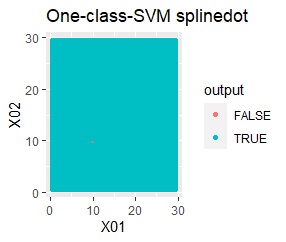
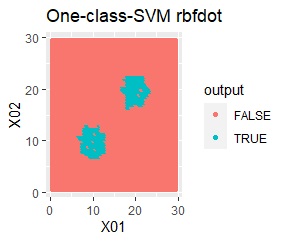
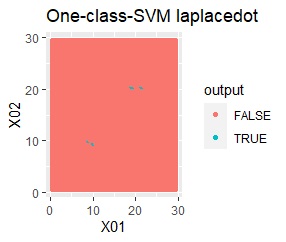
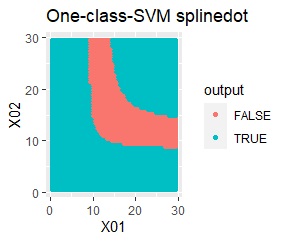
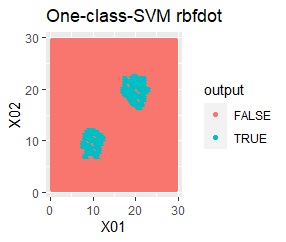
2次元正規分布の塊が2つあります。
2つの塊を捉えらえているのは、rbfdotだけでした。 しかし、TRUEだけで集まっていて欲しい場所にFALSEが少し混ざっています。 品質管理では、良品を不良品として判定することになりますので、良くありません。
この例では、サンプル数は約3000です。 約100000まで増やしたり、nuを調整しても、rbfdotの結果は同じでした。
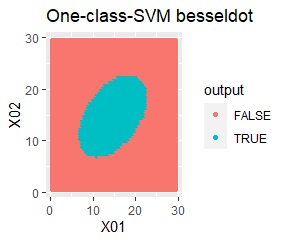
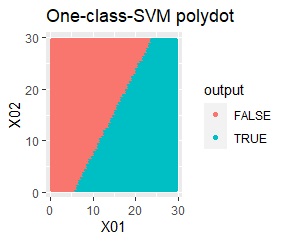
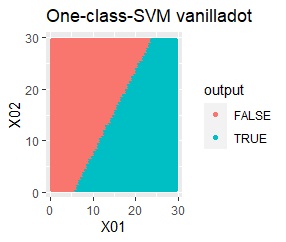
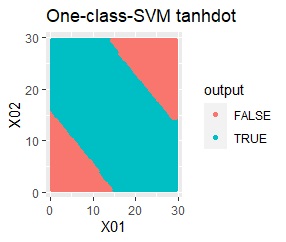
例2Aとほぼ同じですが、外れ値が4つあります。
結果は例2Aとほぼ同じでした。
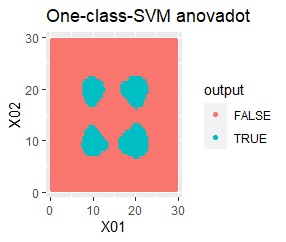
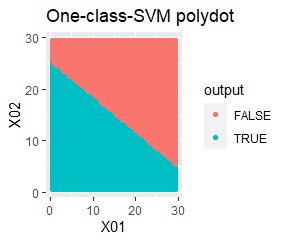
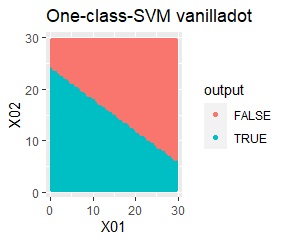
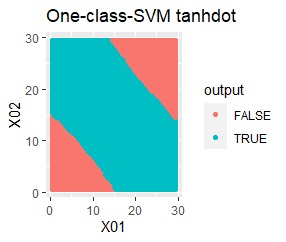
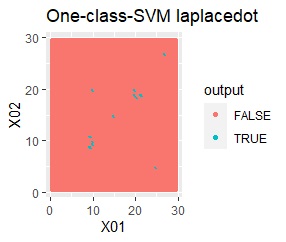
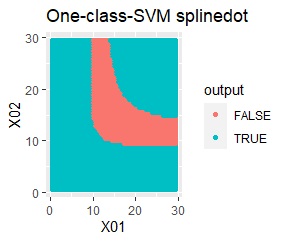
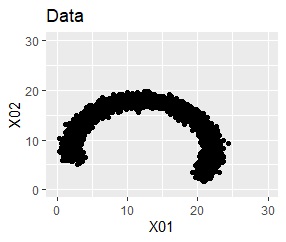
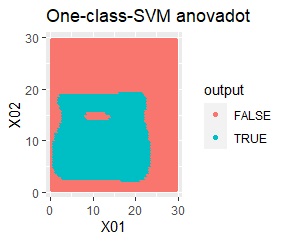
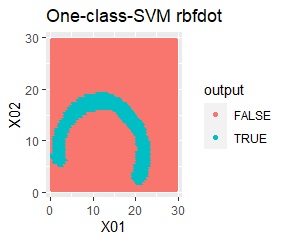
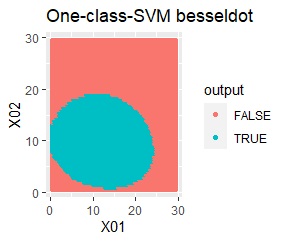
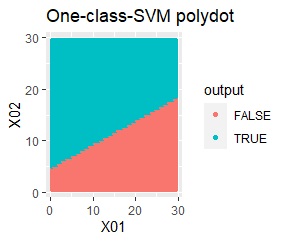
塊はひとつですが、円状ではありません。
rbfdotだけが、良い判定をできました。
R-EDA1 では、異常の判定と、グループ分けの2つの使い方ができます。
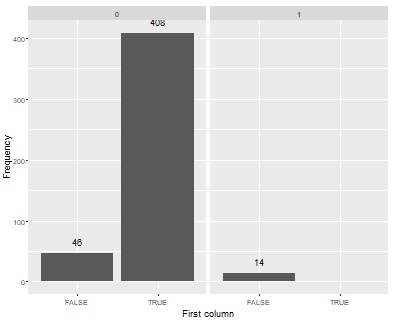
トップメニューからたどって、One_Class_SVM_All_Varaiablesまで行くと、One-Class SVMによる異常の判定ができます。 出力の棒グラフですが、学習データになる0のラベル(単位空間)のデータが左側、1のラベル(信号空間)のデータが右側に来ます。 この方法の特徴として、0側のFALSEが0個にならないのは、想定通りです。 1側にTRUEが出てくると、うまく判別できていないことになります。
カーネル関数は8種類から選べます。 また、学習データで、TRUEとFALSEの割合を調節するためのauというパラメタも変えられるようになっています。
また、One_Class_SVM_Selected_Varaiablesの方を選ぶと、 8種類すべてのカーネル関数と、特徴量が1〜3個の場合のすべての組合せを計算した結果が出せます。



トップメニューからたどって、One_class_SVM_Clusteringまで行くと、One-Class SVMによるグループ分けができます。 「Dimension Reduction」は、この例では「MDS」ですが、「tSNE」でもできます。 ただし、いずれにしても「Add clustering methods」のチェックは必要です。
特徴量の種類と、nuを調節できる点は、上記と同じです。

「サポートベクトルマシン」 竹内一郎・烏山昌幸 著 講談社 2015
数ページですが、1クラスSVMが異常の分析に使える話があります。
「パターン認識」 平井有三 著 森北出版 2012
外れ値の検出の方法として、1クラスSVMが紹介されています。
「異常検知に用いられる1クラスSVMの決定境界をパラメータを変えながら描いてみた」
https://tjo.hatenablog.com/entry/2017/05/28/135918
尾崎隆氏のブログです、nuを変えると、境界に含まれる学習データの量が変えられることが書かれています。
nuのデフォルトは、ライブラリによって違いますが、0.2や0.5くらいになっています。
これを小さくすれば良いそうです。
順路
 次は
MT法
次は
MT法
