 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
外れ値や欠損値、多重共線性、 分布 がでこぼこ、偏り(バイアス)がある、形式が統一されていない、といったデータに対して、 「バッドデータ(悪いデータ)」や「汚いデータ」と呼ぶ人は多いです。
また、変数(データの表の列)が少なかったり、サンプル数(データの表の行)が少なかったりした時に、「これでは何も分からない」とデータ分析をあきらめてしまう人も多いです。これも広い意味でバッドデータです。
では、バッドではないデータは、どんなものかと言えば、それは例えば、大学の研究室のような場所で、測定環境や測定方法を可能な限り厳密に管理して、 測定したデータになります。
ビジネスや社会調査などのデータ分析で使うデータは、どこかがバッドなのが普通です。 このサイトでは、バッドデータについての話が散在しているので、このページでまとめています。
リンク先のある項目は、詳しい話はそちらにあり、ここにあるのは簡単なまとめです。
外れ値や欠損値 は単純に除去することで対策としている解説を、時々見かけます。 このような進め方では、外れ値や欠損値を無視して、外れ値や欠損値以外のデータだけを見ようとしています。
しかし、外れ値や欠損値があるデータでは、「外れ」や「欠損」の理由の調査が先です。
多重共線性 がある場合に、 スパースモデリング などでは、機械的に対応してモデルを作ろうとします。
しかし、多重共線性があるデータでは、多重共線性を手がかりにすると、どのようなデータなのか、データの背景の理解を深めることができます。 そのような観点からデータ分析を始めると、最終的な分析結果がゆるぎないものになって来ます。
ちなみに、 多重共線性 がなく、厳密に各変数の違いを調べるためのデータを手に入れたければ、 実験計画法 を使って実験をするアプローチがあります。 ただし、人為的に実験して集めたデータから得られる結論が、現実に起きていることにどのくらい当てはまるかどうかは、確認がいります。
よく知られている統計学的な手法は、
正規分布
であることを前提としているものが多いです。
このため、「正規性の検定 をして、正規性を確認できていない場合は、使ってはいけない」という考え方をしている人がいらっしゃいます。 また、「平均値ではなく、中央値を使うべき」や、 「ノンパラメトリック検定を使うべき」という考え方をする人もいらっしゃいます。
しかし、「 正規分布ではないのですが、どうすれば良いですか? 」のページに書きましたが、分布がでこぼこな時に、正規分布を前提とした手法を使ったり、平均値を使ったりしても、 ビジネスで起きる問題の解決という目的なら、十分に役に立つことが多いです。
ちなみに、「分布がでこぼこなわけではなく、なめならな山の形だけれども、正規分布とは違う感じ」という時には、 正規分布から作られる分布 や、 一般化線形混合モデル を使うと良い事もあります。
同じ人が体重計に乗るたびに、数kgといった範囲で、値が異なることは普通はないですが、 あまり身近ではない測定値だったりすると、そういった感じで、「ばらつきが大きい」となることがあります。
こういう場合は、データ分析というよりも、データの数字の具体的な値や、値の変化の仕方などを参考にしながら、 データの対象となっている物自体や、測定方法、といったことの調査と改善を進めると、問題の解決につながることがあります。
「アイスクリームの売れ行き」のようなデータ分析について、夏だけのデータで、「冬はこうなります」と言ったら、「おかしい」と誰でも思うかと思います。
機械学習 の分野で「モデルの劣化」と言われますが、これもデータの偏りが原因です。
アンケート のデータなら、「アンケートに答えなかった人」、「アンケートの対象にならなかった人」の意見は入っていないので、やはり偏っています。
基本的な考え方としては、「データはどこかに偏りがある。しかし、それが何かはわからない」と思っていると良いです。 そうしておくと、過度にデータ分析の結果に依存しない対策にしやすくなります。
変数が1個しかないデータに対して、「データ分析は簡単」、「大したことはわからない・できない」と思っている人に、時々お会いします。
しかし、 準周期データの分析 にもありますが、変数が1個でも、かなり大変なこともあります。 また、その大変な作業によって、大きな成果につながるデータ分析になることもあります。
サンプル数が少ないと、「これでは、検証にならない」と判断する人に、時々お会いします。
しかし、そもそも 統計学 というのは、サンプル数が多く取れない時代に発達した学問です。 検定 や 推定 を使うことで、少ないサンプルから、現状の把握や、次の一手を考えるヒントが得られます。
「データが異なるデータベースに分散している」、「同じ意味で、違う言葉が使われている」、「数値データと文字データが混在」、「時刻のデータの形式が複数ある」、「時刻の同期が取れていない」 といったデータもあります。
こういったバッドデータは、統計学的な厳密さとは違う観点でバッドになっています。 こういうバッドデータの場合は、丁寧な前処理が対策になります。
ちなみに、「作業の9割は前処理」と書いているデータ分析の解説が、世の中にたくさんありますが、それは、こういったバッドデータの対策になっています。
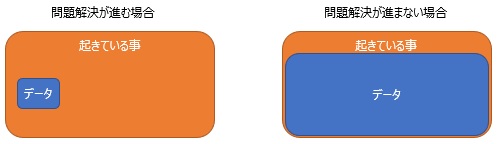
バッドデータだとしても、
問題解決
に貢献するデータ分析にするには、「手元にあるデータは、起きている事のごく一部の何かを表している」という程度に考えて、
「データだけでは、すべてを説明できない」と思っておくことが、心がけとしては一番大事ではないかと思います。
データがカバーしていない部分については、 定性的な仮説の探索 や システム思考 を使って、明らかにしていきます。
いろいろと勉強すると、モデルの精度(当てはまりの度合い)などの数値で、一喜一憂しがちになります。 バッドデータのデータ分析では、バッドなことが前提なので、「憂い」ばかりになりやすいです。 バッドだとしても、 問題解決 につながるデータ分析にするには、複数のアプローチを組み合わせることで、結果の確からしさを上げるようにします。
数式による処理や、数値による判断だけでなく、 グラフ統計 も組み合わせます。
統計学をきちんと勉強するほど起きやすいのですが、データ分析の「良い・悪い」を統計学の前提に合うかどうかで判断しやすくなります。 「正規性の検定をして、正規分布が成り立っていることを確認しないと、その手法は使えない」といった話になりがちです。 バッドデータが当たり前のように含まれているのに、統計学の厳密性にこだわり始めると、統計学を使ったデータ分析が進みにくくなります。
これに陥らないようにするには、成功基準は、あくまで「問題が解決したか(するか)」にします。 統計学については、「問題の解決につながった」、「問題の解決のヒントになった」という程度でOKとします。
バッドデータでは、それらしいモデルができない事が起きます。 「このデータから、精度の高いモデルを作らなければならない」という状況でしたら、ここで行き詰ってしまいます。
しかし、「 データサイエンスの仕事 」のページにあるように、問題解決という目的のために、モデルが重要ではないことは、とても多いです。
モデルができることが重要ではなく、「このデータは、こうなっているんだ。」など、モデルを作る途中で、気付いたことが問題解決で重要なこともあります。
このページでは、「バッドデータは当たり前」として、バッドデータのデータ分析の話をしています。 ところで、統計学的に理想的なデータ、つまり、グッドデータだとしても、「バッドデータは当たり前」ということを知っていると良いです。
実験計画法 で集めたデータは、変数間が独立になるようにしてあるので、理想的なデータです。
しかし、上記の繰り返しになりますが、実験計画法で集めたデータが現実に起きていることを表しているのかは、確認が必要です。 実験をするために、普段は起きないようなことをしていて、それが原因で、データが知りたいことを表していないことがあります。
また、「膨大なデータの中から、実験計画法で計画した条件に当てはまるサンプルだけを集めて来ることで、データセットを作る」 という方法ができてしまう事がありますが、 「当てはまらないサンプル」を除いたことで、何かが失われている可能性があります。
元のデータが偏っていたり、起きている現象に偏りがある状況だったりすれば、 サンプリング したデータが偏っている可能性があります。
「ダークデータ 隠れたデータこそが最強の武器になる」 デイヴィッド・J.ハンド 著 河出書房新社 2021
タイトルの「ダークデータ」というのは、データになっていないデータのことです。
「ダークマター(暗黒物質)」と似た特徴があることから、著者が付けた名前でした。
いわゆる
欠損値
もダークデータの一種です。
また、このサイトの中には、「持っているデータには、何からの偏りがある」という話がありますが、偏ったことで持っていないデータが、
ダークデータの一種です。
著者は、ダークデータを、下記の15種類に分けて、事例で説明しています。
この本の中では、昔から知られているダークデータへの対処法なども説明されていますが、
ダークデータがある可能性を常に意識して、データ分析をしたり結論を考えることの大切さを繰り返し説明しています。
1「欠けていることがわかっているデータ」
2「欠けていることがわかっていないデータ」
3「一部の例だけを選ぶ」
4「自己選別」:「一部の例だけを選ぶ」の変種。自分で選べる場合
5「重要なことを見落とす」
6「あったかもしれないデータ」
7「ときの経過とともに変化する」
8「データの定義」:データの定義がデータの影響する
9「データの集約」:要約によって、データの特徴が隠れてしまう
10「測定誤差と不確かさ」
11「フィードバックループとつけ入り」:データの収集の過程がデータに影響し、その影響が次の収集に影響する
12「情報の非対称性」
13「意図的なダークデータ化」
14「データの捏造または合成」
15「データ外の外挿入」
「バッドデータハンドブック データにまつわる問題への19の処方箋」 Q.Ethan McCallum 著 磯蘭水 監訳 オライリー・ジャパン 2013
データのおかしさの答えがデータ自体にはなく、測定環境にもある例を、製造業の例で取り上げています。
悪いデータの話だけでなくて、このサイトの
もっとデータベース
にあるような話も力説していました。
順路
 次は
ダークデータのイメージ
次は
ダークデータのイメージ
