 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
データには様々な種類がありますので、 データサイエンス を使うような仕事や、データサイエンスが役に立つ仕事も、様々なものがあります。
ところで、 「 データサイエンス でやること = モデルを作って使う」という説明がされることが、世の中ではとても多いです。 「モデルを作る」というのは、 回帰分析 や ディープラーニング などのモデルの係数をデータを使って計算することです。
「モデルを作って使う」だけがデータサイエンスだと思ってしまうと、データサイエンスの仕事も限定されて来ます。 しかし、モデルが重要ではないデータサイエンスの仕事は、どのようなものなのかが、わかりにくいです。
このページでは、モデルが重要な場合と、重要ではない場合を対比する形で、データサイエンスの仕事を整理することにしました。
データサイエンスの仕事にどのようなものがあるのかを考えるには、
モデルが重要な場合と、そうではない場合に分けた方が良いようです。
以下は、その場合分けの説明をしてから、本論になっています。
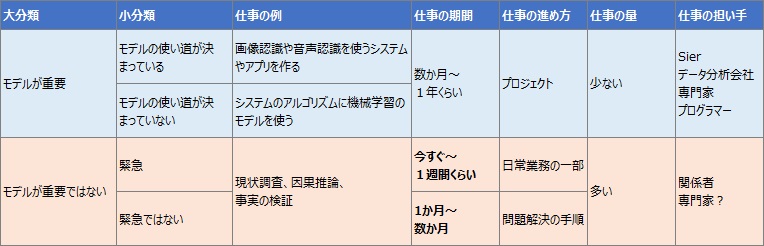
モデルが重要な場合は、さらに、モデルの使い道が最初から決まっている場合と、決まっていない場合に分けた方が良いようです。
モデルの使い道が最初から決まっている場合というのは、 例えば、「画像の中に写っているものを認識する」や、「ユーザーの好みに合うものを選ぶ」という技術を使うことが、最初から念頭にある場合です。
すでにそれらの技術を使うソフトやノウハウがある程度あれば、入力や出力を工夫して、 「アプリやホームページの機能にする」、「ロボットの機能にする」など、いろいろな応用を進めることができます。
様々なモデルについて知っていて、何か新しいことを始めたり、困りごとを解決するために、その知識を活用するケースが当てはまります。
様々なモデルの具体的な数式くらいまで思いを巡らせて、モデルを最初から作り上げていく感じになります。
モデルが重要ではない場合というのは、データの意味や内容を調べたり、考えたりする仕事になって来ます。
データになっている事柄については、データの経緯、背景、精度などに思いを巡らします。 データになっていない事柄についても、考えて行きます。 「この事実の検証には、こういうデータを、こういう風に取る。こういう風にデータを変換する。」、 「選択肢があって迷う時は、こういうデータを取って、こういう風に見る。」と言ったことが、仕事になって来ます。
モデルが重要ではない場合でも、モデルを作ってみることはあるのですが、モデルを当てはめてみることで、 データの内容を確認する使い方になります。 モデルの精度が高いか低いかは見ますが、高いか低いかがわかることが重要で、高くなくても問題ないです。 (機械学習モデルによる因果分析)
精度が高いモデルができると、「やった!これでシステムが作れる」と思いたくなることがあります。 しかし、そのモデルによって原因がわかったのなら、その現象が二度と発生しないようにすることが根本対策になって来ます。 二度と発生しないようになるのなら、「モデルを使って、システムを作ろう」という動きにはならないです。
原因と結果の関係を探る分野として、 因果推論 があります。 世の中に因果推論のモデルはいろいろありますが、実務の中で実際に起こっていることの原因を調べる時のことを考えると、 因果推論は「モデルが重要ではない場合」と考えた方が良いと思います。
モデルが重要ではない場合は、緊急かどうかで分けると良いようです。
「事故発生」、「異常発生」等で、すぐに対応が必要な場合です。
一番最初の応急対応は、経験を中心とした分析をその場でしていて、それの次の段階くらいで、もっと深いデータ分析を実施すると良いことがあります。 被害の拡大を少しでも小さくするためには、急ぎます。
その場所や、その業務の永遠のテーマのような感じになっていて、「なくなると良いのに」と思われていても、未解決になっているような案件が世の中にはあります。
工場ですと、原因不明の不良品の発生や、機械の故障などがあります。
モデルが重要な場合は、それほど急がない場合が多いようです。 早ければ早いほど良かったとしても、数か月から1年くらいを目安にして進めても大丈夫なことが多いようです。
緊急の案件は、早ければ早いほど効果が大きく、遅ければ遅いほど、やることに意味がなくなる場合が多いようです。 「今すぐ」、「今日中」、「長くても1週間以内」といった感じになります。 こういう場合は、結果を出すのが早ければ早いほど、効果が大きいことが多いです。
緊急ではない案件は、数か月くらいの期間でも良いことがあります。 その場合は、数か月かかったとしても、解決できれば効果は大きいです。
モデルが重要な場合は、会計システムや人事システムといったITを導入して会社の業務の効率化を進めて来た取り組みの、 次の段階としてイメージされていることが多いようです。 「ITシステム導入の次は、 人工知能(AI) システムの導入」といった感じです。
モデルが重要な場合は、「 プロジェクト を立ち上げて、システムを作って・・・」という進め方が多いようです。
緊急の場合は、報告書らしい報告書もできず、Excelの画面の中にグラフを1つ作れば完了することもあります。 とにかく早さが重要なことが多いので、「プロジェクトを立ち上げて、・・・」といった進め方ができないです。
緊急ではない場合は、 問題解決の手順 を使うのが良いです。
このサイトにある R-EDA1によるデータ分析 、 Excelによるデータ分析 、 Rによるデータ分析 、 Pythonによるデータ分析 というページは、モデルが重要ではない場合の仕事の中で、筆者自身が使ったノウハウや、「こういうことがしたい」と思ったことを元にしてまとめています。
時間が長かったり、たくさんの人が関わるので、人件費がとてもかかることが多いようです。 また、最終的にシステムや設備を作るように話が進むと、その費用も必要になってきます。
時間が短いですし、場合によっては一人でもできるので、人件費は少ないです。 また、対策として何かをするとしても、お金のかからない改善ができることもあります。
モデルが重要な場合は、コンサルタント会社、データ分析会社と言った会社の方が扱おうとする領域になっています。
一方、モデルが重要ではない場合は、納期の厳しさや、内容の深さが必要なので、こうした会社ではやりにくい領域です。
モデルが重要ではない場合のデータサイエンスの担い手は、その問題や課題の当事者か、それに近い立場で物事を考えることができる人が適任です。
会社の中や社会の中に、モデルを当てはめると良いケースが見つかると、モデルが重要な場合の仕事になって来ます。 例えば、「人が見る作業をしているから、これを画像認識のAIでできるようにしよう」といったことがあれば、仕事になって来ます。
一方、モデルが当てはまるかどうかに関係なく、事実がデータという形になっていたり、データを通して事実がわかるようになっていると良いことが、 会社の中や社会の中には、たくさんあります。 データには、様々なものがありますので、データを使ってやれることは、たくさんあります。
そのため、モデルが重要な仕事と、モデルが重要ではない仕事の量を比べると、後者の方が圧倒的に多いです。
しかし、後者の方は、データサイエンスの仕事として確立されていないのが現状のようです。
例えば、問題を解決するためにデータから原因を見つけるのなら、「原因はこうかもしれない」ということに気付けて、 対策をして問題が解決をするかどうかが成功基準になります。 こういう成功基準で良ければ、手持ちのデータが原因と結果を直接表しているものではなかったとしても、問題解決につなげられることがあります。
筆者にも経験があるのですが、手持ちのデータがどのようなものかに関係なく、とにかくデータにぴったり合って来るモデルを求めるような進め方をすると、 仕事が行き詰まってしまうことが多いようです。
順路
 次は
データ分析の仕事
次は
データ分析の仕事
