 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
1次データの解析 や 1.5次データの解析 では、全体的なデータの内容がわかります。 しかし、 異常状態の工程解析 では、決め手にならないことがよくあります。
扱うデータの種類にもよるのですが、 多変量解析 や データマイニング の手法は、どちらかと言えば、静的な(時間軸で変化しない)データの解析に向いています。 そのため、これらの手法で、1次データのような動的なデータを解析すると、 現象の複雑な変化に数理モデルが当てはまらないために、 「このデータからは、何もわからない。。。」となりかねません。
例の場合は、周期的な変化が特徴ですので、 この特徴を何らかの尺度で表現できると、解析の見通しがよくなります。 このサイトでは、これを「2次データ」と呼んでいます。
また、2次データの解析のデータは、1次データの段階で280行あるのですが、 それがたった5行に集約されています。 解析の負荷が大幅に軽くなっています。 データの複雑さは、列を増やすことによって表現しています。 例のデータでは実感が湧きにくいと思いますが、周期の数が数千、数万となってくると、この集約の効果は絶大です。
1次データ の作成は、データベースからのサンプリングでした。 2次データの作成では、1次データからのサンプリングと、1次データの加工の2つの作業を同時に進めます。
2次データのためのサンプリングは、基本的に 1.5次データの解析 の作成方法と同じです。 ただし、2次データでは、フラグのある行だけを抽出します。 今回の例では、周期の始まりの行だけを抽出します。
2次データの作成は、単純に周期の始まりの行だけの抽出ではありません。 周期の始まりがわかれば、そこを基点にして、その周期の特徴を表す尺度をいろいろと計算することができます。
その周期の間の平均値や、最大値等の統計量の計算も良いですが、 平均値や最大値を求める場合でも、その周期の間のさらに特殊な間隔の間だけを求めると、さらに深い解析ができます。
1次データの加工には、固有技術の知識が総動員されます。 変化のタイミングや、異常な振幅の有無等、統計量以外の尺度を計算しても、深い解析ができます。 良い尺度を作ると、解析後の考察がしやすくなります。
時間の解析用には、タイミングと次のタイミングの差を計算します。 例では、装置が加工中と、停止中が繰り返すので、それらの時間を計算します。 その他に、装置のモードが途中で変わったりするのでしたら、それらの時間を計算することもあります。
周期の始まりの温度の上昇速度、今回は1周期の中にピークが2つあるので、それぞれの値。 また、各モードの、最高、最低の温度、等
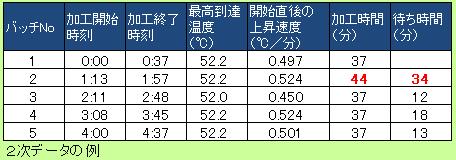
時間のデータを使うと、 稼働時間やチョコ停 の開始ができます。
また、 多変量データの相関分析 、 主成分分析 、 アソシエーション分析 等で、各変数の関係を解析することができます。
2次データ作成のサンプル(Excel編) のページがありますが、これらはExcelのマクロ(VBA)を使った例になっています。
Excelで作っておくと、RやPythonがわからない人でも、普段仕事で使っているExcelを使う感覚で使ってもらえますし、 VBAだといじれる人が多いです。 そのため、筆者の場合は、Excelで処理できるものを作ることが多かったです。
しかし、RやPythonを使えるのなら、大まかな分析を手っ取り早く始められることがあります。 データの切り貼り や メタ知識のデータの作成 の技を使って、 GROUPBYを駆使できるようにデータを作りこみます。 Rによる準周期データの分析 や Pythonによる準周期データの分析 のページは、このようにして作っています。
比較的シンプルな2次データ(特徴量)は、RやPythonを使うとスピーディに分析の段階に進めます。 固有技術を盛り込んだ2次データを作成する場合は、VBAでもRやPythonでも手間はそれほど変わらないです。
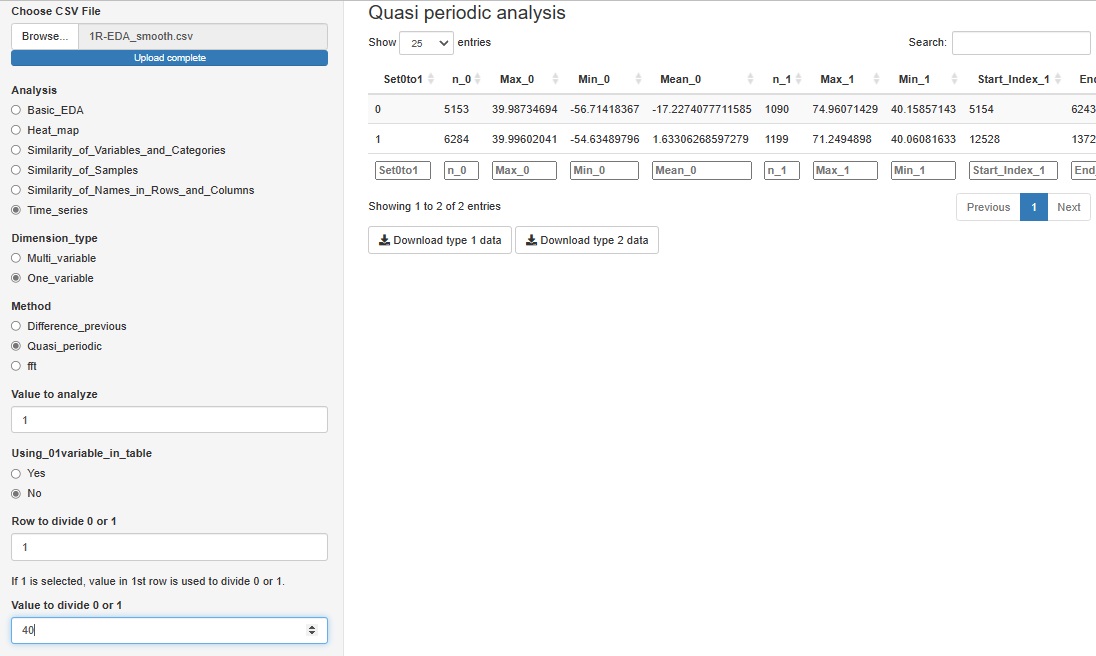
R-EDA1
では、簡単に2次データが作れるようになっています。
「One_variable(一変数)」の中の「Quasi_periodic(準周期)」は、
この機能は、グラフの出力はなく、分析のデータがダウンロードできるようになっています。
必要に応じて、このデータをさらに分析に使うことを想定しています。
準周期性が、1と0の数字で表されている変数があれば、それを使うことができます。
こういった変数がない場合、特定の変数について、「1列目が、40より大きければ1、40以下なら0」というようにして、こうした変数を作ることもできます。
順路
 次は
3次データ(ラベル付きデータ)の解析
次は
3次データ(ラベル付きデータ)の解析
