 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
高次元を2次元に圧縮して可視化 の一般的なアプローチは、「高次元」というところに注目するだけで、高次元の内訳は気にしない手法になっています。
もしも、高次元の中に、2種類に分けられる内訳があるのなら、それを活用した方が、見通しの良い分析になります。
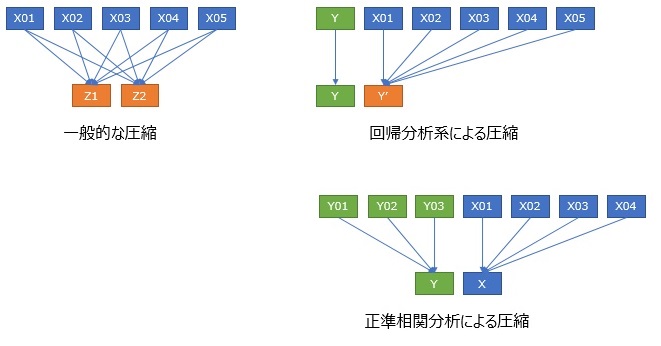
2種類の内訳が、一対多になる場合と、多対多になる場合があります。
一対多になる場合は、目的変数と説明変数に分けられる場合があります。 説明変数側が「多」になります。 回帰分析系で高次元を2次元に圧縮 は、この系統です。
多対多になる場合は、原因系と結果系に分けられる場合があります。 正準相関分析で高次元を2次元に圧縮 は、この系統です。
順路
 次は
回帰分析系で高次元を2次元に圧縮
次は
回帰分析系で高次元を2次元に圧縮
