 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
累積寄与率連関係数というのは、質的変数同士の関係の強さの尺度として、筆者が作ってみたものです。
クラメールの連関係数 や 正規化相互情報量 と同じように使えることを期待していたのですが、いくつか試したところ、だいぶ違う振る舞いをすることがわかりました。
とりあえずは、記録として、このサイトに書きましたが、使い道はわからないでいます。

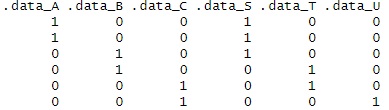

多重共線性 があるので、「カテゴリの数 - 1」個の変数が、元の質的変数と同じものになっています。
例えば、2つの質的変数があって、いずれもカテゴリの数が3個あったとします。 もしも、2つの質的変数がまったく同じなら、ダミー変換して作った変数2個ずつのセットで、同じかどうかを判断できるはずです。
そこから応用して、カテゴリの数が異なる場合は、2つの質的変数について「カテゴリの数 - 1」の大きい方までの個数の累積寄与率を求めることにしました。
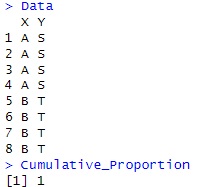
2つの変数に入っているカテゴリの名前は違いますが、下の例だと、AとSは必ずセットですし、BとTは必ずセットです。 これが「構造が同じ」という場合です。
1になります。
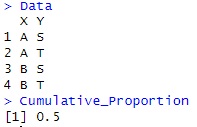
0.5になります。
この点が、
クラメールの連関係数
や
正規化相互情報量
との、大きな違いになります。
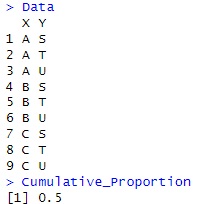
Rによる累積寄与率連関係数 のページのコードで、累積寄与率連関係数の検証をしています。
順路
 次は
要約分析と分解分析の違い
次は
要約分析と分解分析の違い
