Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
累積寄与率連関係数 のRによる実施例です。
library(fastDummies)
setwd("C:/Rtest")
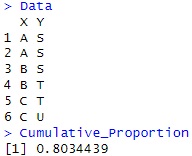
Data <- read.csv("Data.csv", header=T)
Data1 <- dummy_cols(Data[,1], remove_first_dummy = FALSE, remove_selected_columns = TRUE)
ncol1 <- ncol(Data1)
Data2 <- dummy_cols(Data[,2], remove_first_dummy = FALSE, remove_selected_columns = TRUE)
ncol2 <- ncol(Data2)
ncolMax <- max(ncol1, ncol2)
Data12 <- cbind(Data1, Data2)
pca_model <- prcomp(Data12, scale=TRUE) # 主成分分析
Proportion_of_Variance <- pca_model$sdev^2 / sum(pca_model$sdev^2)
Cumulative_Proportion <- sum(Proportion_of_Variance[1:(ncolMax-1)])# 「カテゴリの数 - 1」までの累積寄与率
Cumulative_Proportion