 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
相互情報量 は、最小値はいつでも0なのですが、最大値はカテゴリの数に依存します。
相関係数や寄与率のように、「絶対値が0から1の間」という決まり方をしないため、関係の強さの指標としては使いにくいです。
このページの正規化相互情報量は、いつでも「0から1の間」となる指標として作られたものです。
相互情報量をそれぞれの情報量の平方根で割ります。
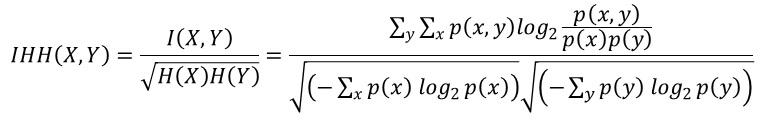
相互情報量は、2つの変数がまったく同じ時に最大値になり、片方の変数の情報量と同じになります。 この時、分母も片方の変数の情報量と同じになるため、1になります。
正規化相互情報量は、共分散と分散で相関係数を求める式と、同じ考え方をしています。
カテゴリ数正規化相互情報量は、筆者が考案したものです。 筆者の知る限りでは、世の中に、同じ指標がないようなので、この名前にしています。
相互情報量を、カテゴリの少ない方の変数の、カテゴリの数の対数で割ります。 こうすることで、0から1の間になります。
この式を対数の法則で変形すると、結果的に、相互情報量の対数を、カテゴリの数に変形した定義式になります。
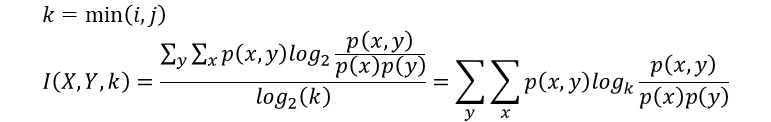
このあたりの考え方は、 平均情報量係数 と同じです。
下図は、カテゴリ数が4個の質的変数で、相関が高いものを2種類用意しています。 いずれも、2つの変数のカテゴリが完全に一致します。
カテゴリ数が4なので、相互情報量の最大値は2(= log(4))になります。 「2」になるのは、左側のパターンの時です。
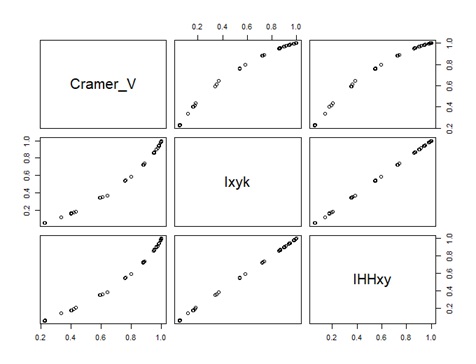
クラメールの連関係数
と似た性質を持つのは、正規化相互情報量です。
カテゴリ数正規化相互情報量は、相互情報量と似ていて、カテゴリ数に偏りがあると、最大値にならないことがわかります。
カテゴリ数正規化相互情報量は、平均情報量は、最大値がわかっていることを利用して、平均情報量とは独立した指標になるようにしています。 2つの質的変数がまったく同じで、さらに、各カテゴリの頻度が同じ(等確率)の時に、最大値の1になります。
正規化相互情報量は、2つの質的変数がまったく同じなら、最大値の1になります。 相関係数と似た振る舞いをするのは、正規化相互情報量の方で、カテゴリ数正規化相互情報量は、相関係数よりも条件が厳しいです。
2つの質的変数がどのくらい似ているのかを測る指標としては、正規化相互情報量が適しています。 カテゴリ数正規化相互情報量は、今のところ、使い道が見当たりません。
Rによる相互情報量 には、入力データの形式別で、正規化相互情報量を求めるコードがあります。
Rによる正規化相互情報量分析 には、変数が2個以上ある時に、すべての組合せについて正規化相互情報量を求める方法があります。
「Mutual information」 WIKIPEDIA 英語版
https://en.wikipedia.org/wiki/Mutual_information
相互情報量のバリエーションが紹介されています。
Normalized Mutual Information(正規化相互情報量)や、uncertainty coefficientもあります。
順路
 次は
有向情報量分析
次は
有向情報量分析
