 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
有向情報量分析は、質的変数同士の関係について、非対称な構造を見つけるための方法の一種です。 有向グラフになるデータの構造 ( 情報量の変化があるデータの構造 ) のひとつとして、 定量的な仮説の探索 に使えます。
有向情報量分析は、 相互情報量 の発展版として、筆者が考えてみたものです。 既に、世の中に同じものがあれば、そちらに合わせますが、筆者の知る限りではないようなので、この名前にしています。
2つの変数があった時に、それらには平均情報量の違いがあります。
有向情報量分析では、この違いに対して矢印を引くのですが、平均情報量だけでは、単に平均情報量の値が違うだけなのか、何らかの関係があることで、その差が生まれているのかが区別できません。
そこで、相互情報量を事前に確認して、相互情報量が高い場合についてだけ、平均情報量の差に着目するようにします。
相互情報量の代わりに、 正規化相互情報量 を使うこともできます。
R-EDA1は、正規化相互情報量を採用しています。
Natto というソフトでは、相互情報量と平均情報量を使うのではなく、uncertainty coefficientを使っています。 uncertainty coefficientは、相互情報量を、いずれかの変数の平均情報量で割ります。 どちらの変数で割るのかで値が異なるため、非対称性の指標になります。 また、相互情報量と平均情報量の両方による評価を、ひとつの指標でできます。
相互情報量と平均情報量を使う方法と、結果がだいたい同じになります。
相互情報量と平均情報量を使う方法は、つながりの強さと、つながりの向きを別に評価できますし、 有向条件付き相互情報量分析 に応用できます。 そのため、筆者としては、相互情報量と平均情報量を使う方法の方が、使い勝手が良いです。
有向情報量分析では、「2つの変数に関係がある」と「2つの変数には平均情報量に差がある」の2つについて、しきい値を超えるかどうかで判断します。
このサイトでは、筆者の経験を元に、前者を0.1、後者を0.0001にしています。
このしきい値について、統計的な厳密性を考えるのなら、検定のアプローチに進んでも良いかもしれません。
有向情報量分析では、平均情報量が高い方から低い方に向かって、矢印を書くようにしています。
平均情報量の高さの違いと、実際のデータの関係については、 平均情報量 のページに例があります。
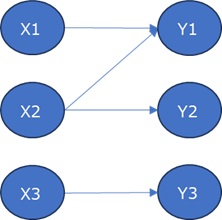
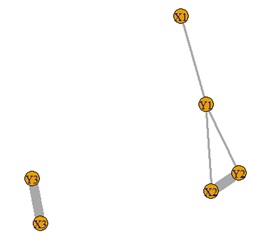
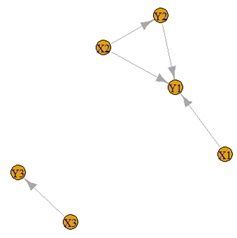
左から順に、元データの構造、相互情報量分析、有向情報量分析です。
元の構造と違うのは、Y1とY2の間に線が引かれていることです。
有向情報量分析では、疑似相関を見破る仕組みがないので、Y1とY2が結ばれます。
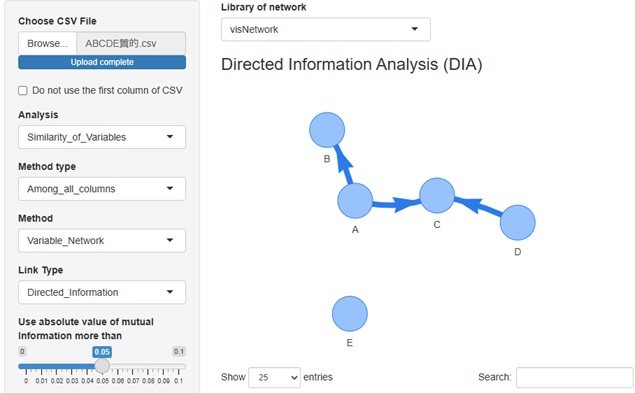
Rによる有向情報量分析 があります。
R-EDA1
で、簡単にできます。
「Natto 情報理論的アプローチによる探索的データ解析ツール」 鈴木了太 他 著
https://ef-prime.com/products/natto/doc/Suzuki_Nagai_and_Taniguchi_2006_revised_20070725.pdf
この論文では、0から1の間になる尺度として、相互情報量をXやYの平均情報量で割った指標を紹介しています。
「uncertainty coefficient (Theil 1970,Goodman and Kruskal 1979)」と呼ばれる指標です。
uncertainty coefficientは、XとYのどちらの平均情報量で割ったのかで、大きさが変わります。
著者は、この指標を「説明力スコア」と呼んで、変数間の強さと非対称性の両方がわかる指標として最小しています。
順路
 次は
有向条件付き相互情報量分析
次は
有向条件付き相互情報量分析
