 僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
暯嬒忣曬検偼丄 忣曬検 偺暯嬒抣偱偡丅
暯嬒忣曬検偼丄乽忣曬僄儞僩儘僺乕乿偲傕屇偽傟傑偡丅 摑寁椡妛 偺僄儞僩儘僺乕偲幃偺宍偑摨偠偱偡丅
暯嬒忣曬検偼丄奺帠徾偺敪惗妋棪偑Pi偺応崌丄
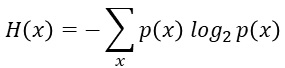
偱偡丅
婲偙傝偵偔偄帠徾傎偳丄抣偑彫偝偔側傝傑偡丅
懡條惈偺広搙偲偟偰丄暯嬒忣曬検傪巊偆応崌偼丄
乽暯嬒忣曬検偑戝偒偄丂亖丂懡條乿
偲偄偆巊偄曽傪偟傑偡丅
懳悢偵偼丄乽掙乮偰偄乯乿偲偄偆傕偺偑偁傝傑偡丅
懳悢偼丄條乆側暘栰偱巊傢傟傑偡偑丄偦傟偧傟偺暘栰偵傛偭偰丄傛偔巊傢傟傞掙偺悢帤偑堘偄傑偡丅 懳悢偺掙偼丄10偵偟偨傝丄僱僀僺傾悢e乮2.71828丒丒丒乯傪巊偭偨傝偟傑偡丅
僜僼僩偱傕堘偭偰偄傑偡丅 EXCEL偺LOG偲偄偆娭悢偼丄僨僼僅儖僩偑10偵側偭偰偄偰丄掙傪巜掕偟側偄偱巊偆偲丄10偲偟偰寁嶼偝傟傑偡丅 R偺log偲偄偆娭悢偱偼丄僨僼僅儖僩偑僱僀僺傾悢偵側偭偰偄傑偡丅 椺偊偽丄EXCEL傗丄R偱丄掙傪俁偵巜掕偟偨偄応崌偼丄log( X ,3)偲彂偒傑偡丅 EXCEL偵LOG10丄R偵log10偲偄偆娭悢偑偁傝丄偙傟傜偼掙偑10偱屌掕偱偡丅 EXCEL偱偼丄LN偲偄偆娭悢傪巊偆偲丄掙偑僱僀僺傾悢偺懳悢傪寁嶼偱偒傑偡丅
暯嬒忣曬検偼丄偄傠偄傠側暥專偱弌偰棃傑偡偑丄懳悢偺掙傪彂偄偰偄側偄暥專偑偲偰傕懡偄偱偡丅 彂偄偰偁傞傕偺偵偼丄乽2乿偲彂偄偰偁傞偺偱丄乽2乿偑堦斒揑側掕媊偺傛偆偱偡丅
僨乕僞暘愅傪偡傞帪偼丄僨僼僅儖僩偱懳悢傪巊偭偰傕栤戣偺側偄偙偲偑懡偄偱偡偑丄暯嬒忣曬検傪帺暘偱寁嶼偡傞帪偼丄掙傪巜掕偡傞昁梫偑偁傝傑偡丅
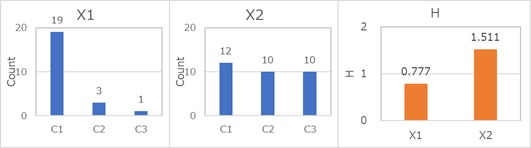
暯嬒忣曬検偼丄昿搙偺偽傜偮偒偑戝偒偗傟偽戝偒偄傎偳丄侽偵嬤偔側傝傑偡丅
摍妋棪丄偮傑傝丄奺僇僥僑儕偺昿搙偑摨偠帪偵丄嵟戝抣偵嬤偔側傝傑偡丅
惓妋側徹柧偼丄昅幰偼妋擣偱偒偰偄側偄偺偱偡偑丄暯嬒忣曬検偺嵟戝抣偼丄埲壓偺幃偱媮傑傞傛偆偱偡丅
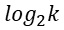
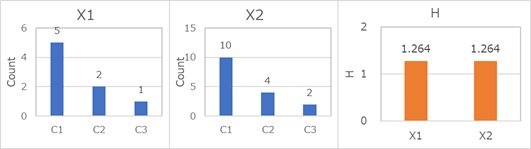
k偲偄偆偺偼僇僥僑儕偺悢偱偡丅 椺偊偽丄A偲B偲偄偆僇僥僑儕偟偐側偄幙揑曄悢側傜丄k偼2偱丄忣曬検偺嵟戝抣偼丄偪傚偆偳1偲偄偆偙偲偵側傝傑偡丅 僇僥僑儕偺悢偑4側傜丄k偼4偱丄忣曬検偺嵟戝抣偼丄偪傚偆偳2偱偡丅
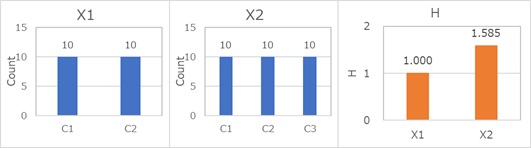
暯嬒忣曬検偼丄 幙揑曄悢偺偽傜偮偒偺広搙 偵側傝傑偡丅
暯嬒忣曬検偼丄昿搙偺偽傜偮偒偺戝偒偝偲丄僇僥僑儕偺悢偺椉曽偱寛傑傝傑偡丅
暘嶶傗昗弨曃嵎偼丄乽偽傜偮偒偑戝偒偄傎偳丄戝偒偄乿偲偄偆広搙側偺偱丄堦尒偡傞偲丄媡偺傛偆偵尒偊傑偡丅
堦曽丄乽昿搙偺偽傜偮偒偑戝偒偄乿偲偄偆偺偼丄傂偲偮偺僇僥僑儕偵曃偭偰偄傞偲偄偆偙偲側偺偱丄 乽昿搙偺偽傜偮偒偑彫偝偄曽偑丄傑傫傋傫側偔偽傜偮偄偰偄傞乿偲偄偆尒曽傕偱偒傑偡丅 暘嶶傗昗弨曃嵎偲偼丄屻幰偺曽偺峫偊曽傪偡傞偲丄抣偺弌曽偑崌偭偰偄傑偡丅
乽忣曬検乿丂biopapyrus
https://bi.biopapyrus.jp/seq/entropy.html
忣曬僄儞僩儘僺乕偺庢傝摼傞斖埻偑丄侽偐傜丄僇僥僑儕偺悢偺懳悢偺娫偵側傞偙偲偑帵偝傟偰偄傑偡丅
弴楬
 師偼
暯嬒忣曬検學悢
師偼
暯嬒忣曬検學悢
