 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
手法による得意な分布の違い のページでは、手法の違いについて、「適した分布」という見方でまとめています。
このページでは、同じ分布について、手法が違うと結果がどのように違うのかをまとめてみました。 「予測」や「判別」を目的にして、これらの手法を使う時には重要な知識になります。
このページの計算は、Excelでサンプルデータを作り、RapidMinerで予測値を出して、結果をExcelでグラフにしています。 Excelの部分は、サンプルファイルにExcelの具体例があります。
MT法 は、Yの2値の扱い方が同じではない点が、他の手法と比べると異質なので、このページには入れていません。
RapidMinerの部分は、 予測のためのソフトの使い方 で計算を組みました。
文字データは、「Polynominal」としてソフトが自動認識しますが、手法によっては、これだとエラーになります。 この場合は、「Binominal」に変更すると良いです。
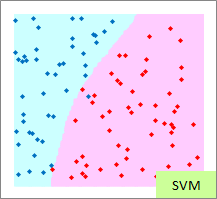
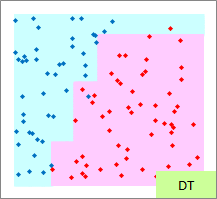
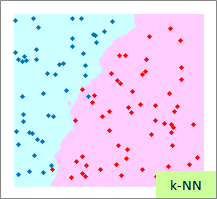
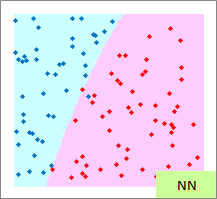
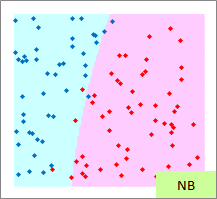
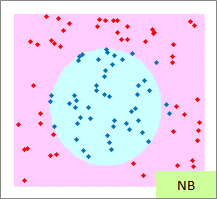
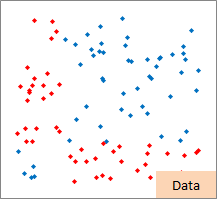
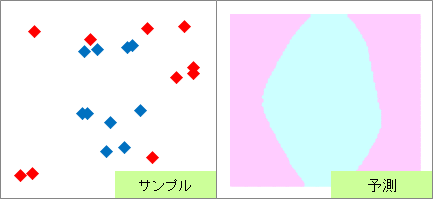 赤い点と青い点で描かれたサンプルのグラフは、モデルを作る元になるデータです。
元データの「-1」が赤い点、「1」が青い点になるようにしています。
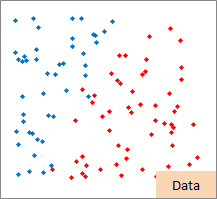
赤い点と青い点で描かれたサンプルのグラフは、モデルを作る元になるデータです。
元データの「-1」が赤い点、「1」が青い点になるようにしています。
予測のグラフは、グラフの範囲の全部で、細かく予測した結果になります。 ピンクが「-1」と予測されるところ、水色が「1」と予測されるところになります。
実際の結果のグラフは、サンプルと予測を重ねた方がわかりやすいので、重ねています。
RapidMinerでは、 ロジスティック回帰分析 に カーネル法 が使えます。 そのため、必ずしも 手法による得意な分布の違い のページの内容と合わない部分があります。
どれが一番良いのかは、その時その時の目的やデータの内容によりますので、 あくまで、「このページの比較の場合」と理解していただければ、と思います。
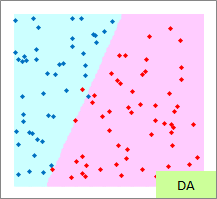
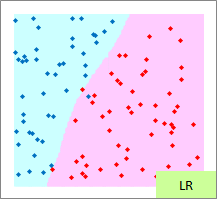
例1のモデル作成用ファイルのリンク を使って、作っています。
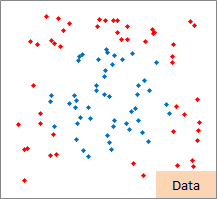
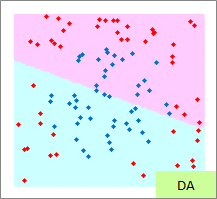
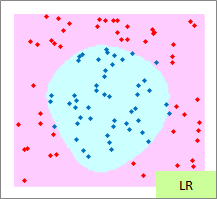
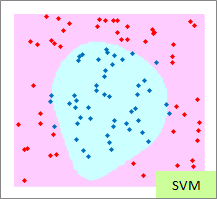
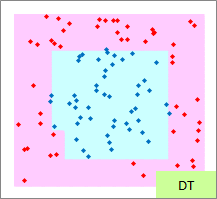
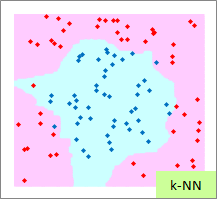
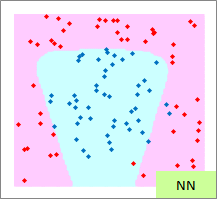
例2のモデル作成用ファイルのリンク を使って、作っています。
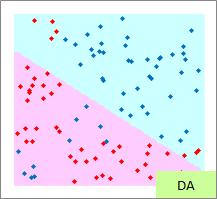
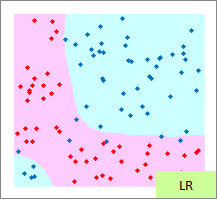
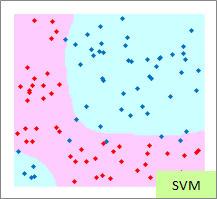
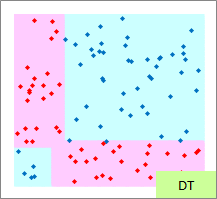
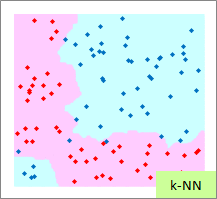
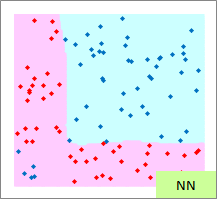
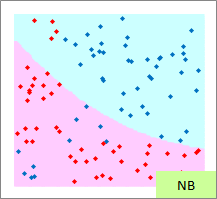
例3のモデル作成用ファイルのリンク を使って、作っています。
このページの解析は、赤か青のどちらかが予測値になるようにしていますが、 手法によっては、「赤の確率、青の確率」という、あいまいさの情報も計算されています。
また、モデルの妥当性は、定量的な評価方法が、いくつかあります。 とはいえ、グラフの見た目でも、だいたいわかると思います。
順路
 次は
変数の類似度の分析
次は
変数の類似度の分析
