 僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
LiNGAM 偼丄峔憿儌僨儖偺學悢傪媮傔傞曽朄側偺偱丄 曄悢偺椶帡搙偺暘愅 偵巊偆帪偵偼丄傂偲岺晇昁梫偵側傝傑偡丅
昗弨壔傗惓婯壔 偑丄偦偺岺晇偵側傝傑偡丅
偙偺岺晇偼丄 LiNGAM偺尷奅 偵側偭偰偄傞僨乕僞偱傕娫堘偊偢偵暘愅偡傞偨傔偺岺晇偲偟偰巊偊傑偡丅
LiNGAM偺尷奅 偵偁傞榖偺偆偪丄乽曅曽偺岆嵎偑嬌抂偵戝偒偄帪乿丄乽曅曽偺岆嵎偑嬌抂偵彫偝偄帪乿丄乽學悢偑嬌抂偵彫偝偄帪乿偵偮偄偰偼丄 昗弨壔傗惓婯壔 傪偟偰傕丄憡懳揑側戝偒偝偺娭學偼曄傢傜側偄偺偱丄岠壥偼偁傝傑偣傫丅
乽學悢偑嬌抂偵彫偝偔偰丄曅曽偺岆嵎偑嬌抂偵彫偝偄帪乿偵偮偄偰偼丄
昗弨壔傗惓婯壔
傪偡傞偲丄寢壥偑曄傢傝傑偡丅
乽學悢偑嬌抂偵彫偝偔偰丄曅曽偺岆嵎偑嬌抂偵彫偝偄帪乿偱崲傞偺偼丄0偱偁偭偰梸偟偄偲偙傠偑0偱側偔側傝丄
0偵側偭偰梸偟偔側偄偲偙傠偑0偵側傞偙偲偱偟偨丅
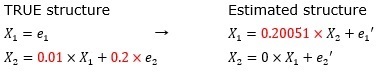
偟偐偟丄椺偊偽丄LiNGAM偺慜偵奺曄悢傪昗弨壔偟偰偍偔偲丄寢壥偼壓婰偵側傝傑偡丅
乽0.01乿偲偄偆悢帤偑媮傑傞栿偱偼側偄偺偱偡偑丄彮側偔偲傕丄幃偺峔憿偼娫堘偊側偄偱嵪傒傑偡丅
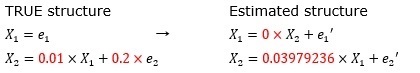
搨撍偱偡偑丄LiNGAM偺寢壥偲偟偰丄壓婰偺幃偑媮傑偭偨偲偟傑偡丅
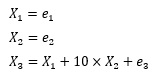
學悢偺戝偒偝傪尒傞偲丄X3偵懳偟偰丄X1偑1偱丄X2偑10偱偡丅 偟偐偟丄偙偺忣曬偐傜乽X2偺曽偑X3偲偺娭學偑嫮偄乮憡娭偑戝偒偄乯乿偲偄偆寢榑傪弌偡偺偼娫堘偄偵側傝傑偡丅
X3傪廲幉偵偟偰丄X1偲X2傪墶幉偵偡傞偲丄壓偺僌儔僼偩偭偨偲偟偰傕丄LiNGAM偱忋婰偺寢壥偵側傞偙偲偑偁傝傑偡丅
偙偺僌儔僼傪尒傞偲丄X3偲娭學偑嫮偄偺偼丄X1偺曽偱偡丅
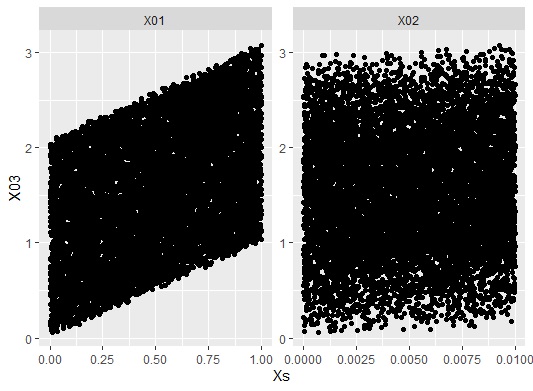
偙偺尰徾偼丄e1丄e2丄e3偺偽傜偮偒偺戝偒偝偑嬌抂偵堘偆偲婲偙傝傑偡丅
廳夞婣暘愅 傪偡傞帪偵丄扨埵偺堎側傞曄悢摨巑偵偮偄偰丄栚揑曄悢Y傊偺塭嬁搙傪尒偨偄応崌丄扨弮偵廳夞婣暘愅傪偟偨帪偺奺曄悢偺學悢偱偼側偔丄 昗弨曃夞婣學悢傪尒側偄偲丄娫堘偄偵側傝傑偡丅 學悢偺扨埵偑偦傟偧傟堎側傝丄扨埵偺堎側傞悢帤傪斾妑偡傞偙偲偵側傞偨傔偱偡丅
昗弨曃夞婣學悢偲偄偆偺偼丄奺曄悢傪昗弨壔偟偰偐傜廳夞婣暘愅傪偡傞偲媮傑傞學悢偱偡偑丄偙傟傪巊偆偲丄扨埵偑摨偠偵側傞偨傔丄 忋婰偺娫堘偄偑側偔側傝傑偡丅
偙傟偲摨偠偙偲偑丄LiNGAM傪巊偭偰丄曄悢偺娭學偺嫮偝傪尒傞帪偵傕婲偒傑偡丅 偦偺偨傔丄曄悢偺慜張棟偲偟偰丄 昗弨壔傗惓婯壔 傪偡傞昁梫偑偁傝傑偡丅
昗弨壔傗惓婯壔 傪偟偰偍偔偲丄學悢偺悢帤偑偦偺曄悢偺塭嬁搙傪昞偡悢帤偲偟偰巊偊傞傛偆偵側傝傑偡丅
忋婰偺椺偺応崌偼丄昗弨壔傪偟偰偐傜LiNGAM傪偡傞偲丄壓偺寢壥偵側傝傑偡丅
X1偺學悢偺曽偑丄X2偺學悢偺10攞偁傝丄娭學偺嫮偝偑學悢偺戝偒偝偱尒偊傞傛偆偵側偭偰偄傑偡丅
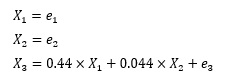
壓偺椺偺応崌丄堦斣嵍偑僨乕僞偺峔憿丄恀傫拞偑昗弨壔側偟丄堦斣塃偑昗弨壔偁傝偱偡丅
昗弨壔偁傝偼丄偍偐偟側寢壥偵側偭偰偄傑偡丅
昗弨壔傪偡傞偲丄曄悢娫偺幃偺娭學偑曵傟傞偺偱丄偙偺傛偆側帠偑婲偒傞傛偆偱偡丅
偙偺椺偺応崌偼丄昗弨壔偼偟側偄曽偑惓偟偄偱偡丅
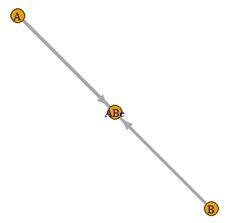
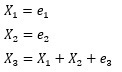
偲偄偆峔憿幃偵側偭偰偄傞曄悢偑偁偭偨偲偟傑偡丅
偙偺応崌丄e1丄e2丄e3偺岆嵎崁偑丄偡傋偰摨偠偔傜偄偺斖埻偱偽傜偮偔帪偼丄LiNGAM偱峔憿幃傪惓偟偔悇掕偱偒傞偺偱丄 曄悢偺娭學惈傪惓偟偔暘愅偱偒傑偡丅
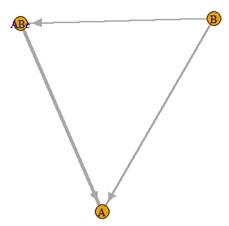
偲偙傠偑丄e3偩偗偑嬌抂偵彫偝偄応崌丄
埲壓偺俁偮偺幃偑摨偠側偙偲偲帡偨忬懺偵側傞偨傔丄LiNGAM偱峔憿傪摿掕偡傞偙偲偑偱偒側偔側傝傑偡丅
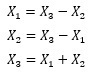
偙偺栤戣偼丄 昗弨壔傗惓婯壔 偱傕丄夝寛偟側偄偱偡丅
偨偩偟丄乽曄悢偺娭學偼懌偟嶼偟偐惉傝棫偨側偄偼偢乿偲偄偆慜採偑抲偗傞応崌偼丄 乽儅僀僫僗偺晞崋偼丄擣傔側偄乿偲偄偆忦審傪傾儖僑儕僘儉偵晅偗傟偽丄夝寛偡傞偐傕偟傟傑偣傫丅
R-EDA1 偱偼丄昗弨壔傗惓婯壔傪偟偰曄悢偺娭學傪傒傞暘愅偑丄娙扨偵帋偣傑偡丅
弴楬
 師偼
庡惉暘暘愅
師偼
庡惉暘暘愅
