 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
クラスター分析は、
サンプルの類似度の分析
の一種です。
この分析をすると、データのグループ(クラスター)を作ることができます。
例えば、左の散布図は、3つのグループに分かれそうに見えますが、この方法を使うと、
それぞれのサンプルのグループ分けを、ソフトが自動的にやってくれます。
作られたグループの情報を使えば、色分けもできます。
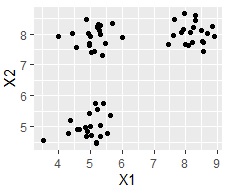
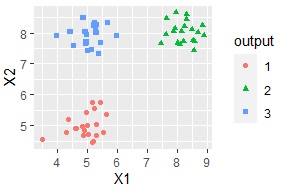
クラスター分析 は、多変量解析や機械学習のたいていの本で解説されているような方法ですが、実務で多次元データに使おうとすると「あれ?」となることがあります。 それは、「クラスター分析の手法が、うまくクラスターを作れたのかがわからない」、という問題です。
2次元や3次元のデータなら、クラスターがうまく作れているのかをグラフで確認できるので、 「うまく作れました」という解説をする時は、2次元や3次元のデータが使われることがあります。 手法を勉強する時は、このような確認の仕方で良いとは思うのですが、 4次元以上になって来ると、この方法が使えません。
この問題の解決策のひとつが、 クラスタリングの原因分析 になります。
「 高次元を2次元に圧縮して可視化 の方法を使ってから、 クラスター分析 をする」 、という方法があります。 これだと、 クラスター分析 が扱うデータは2次元になっているので、上記の問題が起きません。
また、 高次元を2次元に圧縮して可視化 の方法だけだと、「サンプルは3つのグループに分かれます」という説明をしたい時に、「3つのグループ」の色分けは、人がすることになるのですが、 この色分けのための情報をクラスター分析で作ることができます。
この方法については、 2次元散布図を使ったクラスター分析 のページがあります。
Rによる実施例は、 Rによるサンプルの類似度の分析 のページにあります。
順路
 次は
クラスター分析の方法
次は
クラスター分析の方法
