 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
クラスター分析 をする時に悩むところは2つあります。
1つは、3次元以上で非階層型のクラスター分析をすると、 グループ分けとデータの関係を見ることに適したグラフがないことです。 この悩み事の解決法として、 2次元散布図を使ったクラスター分析 はあるのですが、この方法はどちらかと言うと、サンプル数が少ない時に向いています。
悩みどころのもう1つは、 2次元散布図を使ったクラスター分析 では難しいことには、 クラスタリングの結果がそうなった理由がわからない点です。 クラスター分析のアルゴリズムは探索的にクラスターを作るので、 結果として、どのようなクラスターになるのかはわかるのですが、「どうしてこのクラスターになるのか?」ということが、わからないです。
これらの2つの悩み事の解決策として、 決定木 が役に立ちます。 なお、決定木を使う方法では、個々のサンプルを詳しく見ることはできないので、 2次元散布図を使ったクラスター分析 とは、相補的な関係になります。
手順としては、クラスター分析で作ったクラスターの情報を、目的変数として、 ラベル分類 の手法を使うことになります。
教師なし学習 のデータに対して、教師あり学習の手法を使う分析方法の一種になります。
ラベル分類 の手法なら、決定木以外でも使えなくはないのですが、決定木には、 「目的変数が質的変数で、しかも、多クラスでも良い」、「分析結果の説明性がある」という特徴があるので、このアプローチには便利です。
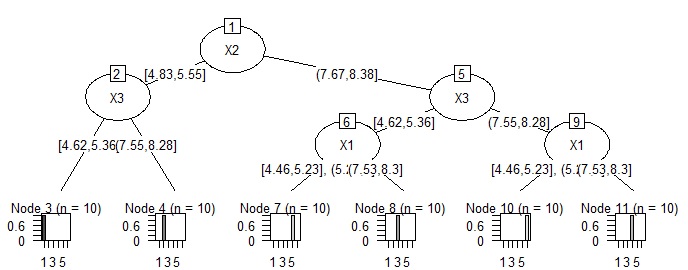
クラスター分析の結果(クラスターの番号等)を目的変数にして、 クラスター分析で使ったデータを説明変数にして、 決定木 を実行します。
すると、クラスターがどのように分けられているのかが、決定木の結果からわかります。
Rによる実施例は、
Rによるクラスタリングの原因分析
のページにあります。
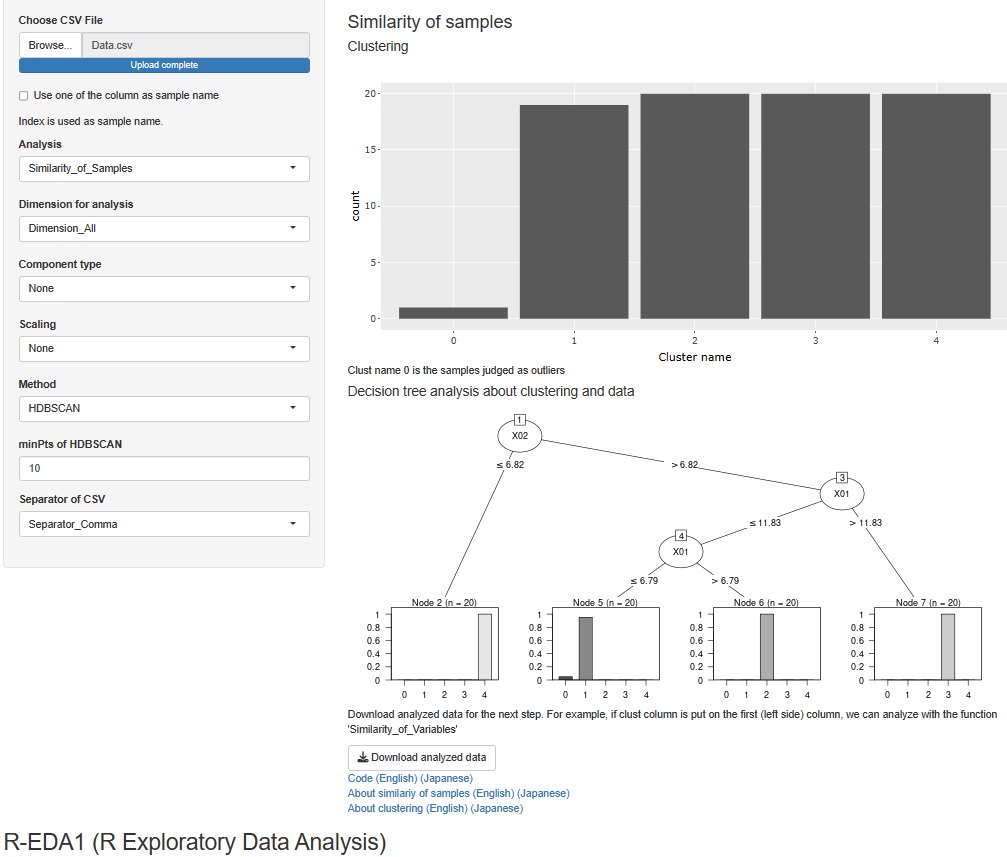
R-EDA1
では、混合分布法やDBSCANをすると、C5.0による決定木分析が出てくるようになっています。
順路
 次は
次元削減クラスタリング分析
次は
次元削減クラスタリング分析
