Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
クラスタリングの原因分析 では、 クラスター分析のクラスターがなぜ、そのようになったのかは、クラスター分析からはわからないため、 クラスター分析以外の方法を使って調べます。
決定木 を使って調べます。
この例では、Cドライブの「Rtest」というフォルダに、
「Data1.csv」という名前でデータが入っている事を想定しています。
ここで使っているデータは、3次元空間に6個のグループがある場合です。
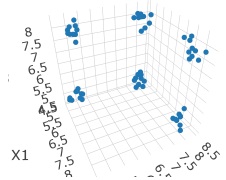
# まず、入力データを用意します。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data10 <- read.csv("Data1.csv", header=T) # データを読み込み
Data11 <- (Data10 - apply(Data10,2,min))/(apply(Data10,2,max)-apply(Data10,2,min))# すべての変数のデータを、0から1の間のデータにする。
# クラスター分析をします。
library(dbscan) # ライブラリを読み込み
dbs <- dbscan(Data11, eps = 0.2) # DBSCANで分類。epsは、コア点からの距離の範囲です。ここでは、0.2にしました。
output <- dbs$cluster # 分類結果の抽出
Data <- cbind(Data10, output) # 最初のデータセットにグループ分けの結果を付ける
Data$output <-factor(Data$output) # グループの変数を文字列型にする
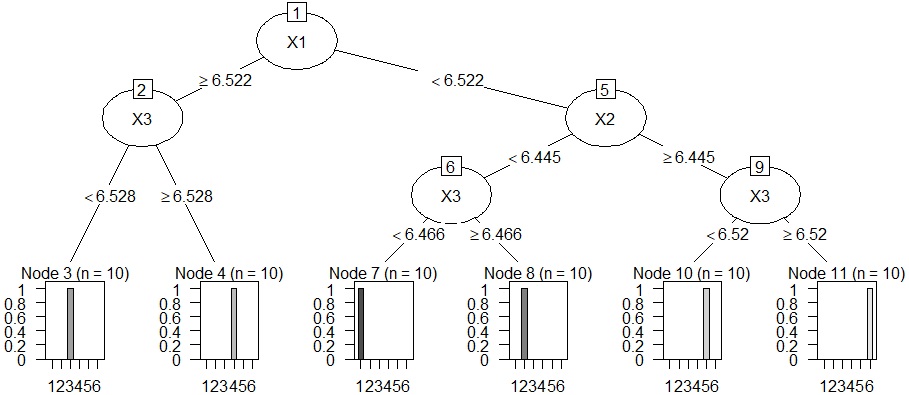
# 決定木をrpartにする場合です。
library(partykit) # ライブラリを読み込み
library(rpart) # ライブラリを読み込み
treeModel <- rpart(output ~ ., data = Data)# rpartを実行
plot(as.party(treeModel)) # グラフにする。
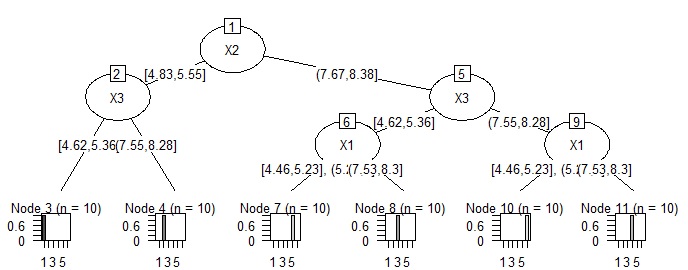
# 決定木をCHAIDにする場合です。
量的データを質的データにする手間があります。
この例では、その手間の効果がわかりませんが、
N進木
になるので、データの構造が複雑な時に理由の考察がしやすくなります。
library(CHAID) # ライブラリを読み込み
Data <- read.csv("Data.csv", header=T, stringsAsFactors=TRUE) # データを読み込み
Data$X1 <- droplevels(cut(Data$X1, breaks = 5,include.lowest = TRUE))# 5分割する場合。元のデータに質的データを追加する。
Data$X2 <- droplevels(cut(Data$X2, breaks = 5,include.lowest = TRUE))# 5分割する場合。元のデータに質的データを追加する。
Data$X3 <- droplevels(cut(Data$X1, breaks = 5,include.lowest = TRUE))# 5分割する場合。元のデータに質的データを追加する。
treeModel <- chaid(Y ~ ., data = Data)# CHAIDを実行
plot(treeModel) # グラフにする。