 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
データマイニング の事例として、ビールとオムツの話は有名です。 アソシエーション分析は、この事例のような分析ができる手法です。
「アソシエーション・ルール」、「連関規則」、「マーケット・バスケット分析」とも呼ばれています。
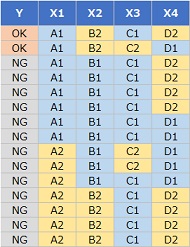
上のようなデータがあったとします。
よく見ると、
「X1 = A1 かつ X2 = B2 ならば 必ず Y = OK」
となっています。
また、
「X1 = A2 ならば 必ず Y = NG」
となっています。
上のデータをアソシエーション分析した結果の例が、下図になります。
「X1 = A1 かつ X2 = B2 ならば 必ず Y = OK」は赤色の丸、「X1 = A2 ならば 必ず Y = NG」は黄色の丸として、抽出されています。
「ならば」と矢印の向きが対応しています。
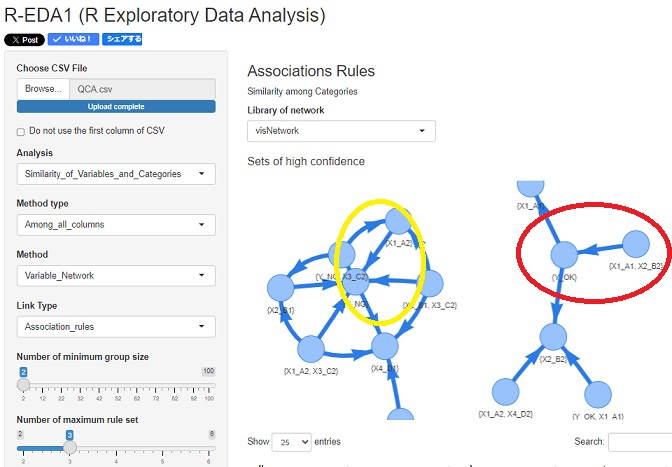
この分析例では、必ず言える2つのルールの他に、必ずと言えないけれども、確度の高いルールも抽出されています。
アソシエーション分析は、 カテゴリの類似度の分析 の代表的なものです。
データ分析の手法として、よく知られているものは、 変数の類似度の分析(回帰分析など) がとても多く、次が、 サンプルの類似度の分析(クラスター分析など) と思います。
アソシエーション分析では、Y、X1、X2といった変数の近さを調べているのではなく、Y、X1、X2の中にあるOK、A1、B1といったカテゴリ同士の近さを調べています。
確信度は、XとYを入れ替えて計算すると、違う値なので、2つの変数に対して非対称です。 矢印のついたネットワークグラフを描くことができます。
支持度は、2つの変数に対して対称的です。
ラフ集合分析 には独自のアルゴリズムで、ラフ集合を見つける方法が紹介されています。
アソシエーション分析のアルゴリズムは、 ラフ集合分析 にも使えます。
上の例は、 R-EDA1を使っています。
上のようなサンプルデータの場合、OKになっているサンプルが2つしかないです。 OKになっているグループを抽出するため、「Number of minimum group size」は「2」に設定しています。 また、OKに必ずなるルールを見つけるには、YとX1とX2の3つの変数を見る必要があるため、「Number of maximum rule set」は「3」に設定しています。 この例の場合は、4以上にしても、結果は変わりません。
「Number of minimum group size」は小さければ小さいほど、「Number of maximum rule set」は大きければ大きいほど、計算するルールが多くなるので、計算時間が増えます。
サンプルデータは、質的変数ですが、R-EDA1は、量的変数は1次元クラスタリングをして質的変数(区間データ)に変換します。 そのため、量的変数でも分析できます。
Rによる実施例は、 Rによるアソシエーション分析 にあります。
Natto
の「ローカル」という方法は、アソシエーション分析になっています。
「データマイニング入門 :Rで学ぶ最新データ解析」 豊田秀樹 編著 東京図書 2008
入力データが、「① 質的データのそれぞれが、変数になっていて、「あり・なし」が1と0で表されている形式」と、
「② 表形式になっていて、質的変数として、質的データが入っている形式」
の2種類について、Rの実施例があります。
この本では、①と②の違いは、matrixにする行を入れるかどうかの違いだけです。
このサイトの実施例では、量的データが混ざっている場合に、質的データに変換してから使うコードを入れたこともあり、、
①と②のどちらでも大丈夫です。①の時は、何の心配もいらないのですが、②の時は量的データの1行目が整数だと、
その列はダミー変換がされません。読み込むファイルの1行目は、25.0等の小数点を含むデータにしてください。
パラメータの設定の仕方も詳しいです。
同志社大学 金明哲先生のページ
入力データが、「各サンプルが質的データのセットになっている形式」になっている場合が、Rの実施例になっています。
https://www.cis.doshisha.ac.jp/mjin/R/40/40.html
「フリーソフトではじめる機械学習入門」 荒木雅弘 著 森北出版 2014
アソシエーション分析では、計算する組み合わせが膨大になるため、
優先度の高い組み合わせだけが計算されるようになっています。
そのアルゴリズムは、アプリオリアルゴリズムや、FP-Growthアルゴリズムと呼ばれるものですが、これらのアルゴリズムを図解しています。
Albert社のページ
各指標が、図解されていてわかりやすいです。リフトが1より小さい時は、おすすめしないようにするそうです。
https://www.albert2005.co.jp/knowledge/marketing/customer_product_analysis/abc_association
順路
 次は
コレスポンデンス分析
次は
コレスポンデンス分析
