 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
カテゴリの類似度の分析 の方法です。
基本的には質的変数に対しての方法ですが、量的変数は、 1次元クラスタリング の方法で、質的変数に変換するコードが入っているので、 質的・量的が混合していたり、量的変数だけでも使えるようにしてあります。
量的変数だけの場合は、変数の非線形の関係を分析する方法として使えます。
アソシエーション分析 と ネットワークグラフ の合わせ技の方法です。
setwd("C:/Rtest") # 作業用ディレクトリを変更
library(arules) # ライブラリを読み込み
library(fastDummies) # ライブラリを読み込み
library(igraph) #ライブラリを読み込み
library(ggplot2)# ライブラリを読み込み
Data <- read.csv("Data.csv", header=T) # データを読み込み
for (i in 1:ncol(Data)) { # ループの始まり。データの列数を数えて同じ回数繰り返す
if (class(Data[,i]) == "numeric") { # 条件分岐の始まり
Data[,i] <- droplevels(cut(Data[,i], breaks = 5,include.lowest = TRUE))# 5分割する場合。量的データは、質的データに変換する。
} # if文の処理の終わり
} # ループの終わり
for (i in 1:ncol(Data)) {
if (class(Data[,i]) == "character") {
Data <- dummy_cols(Data,remove_first_dummy = FALSE,remove_selected_columns = TRUE)
break
}
}
Data3 <- as(Data, "matrix")# マトリックス形式にする
Data4 <- as(Data3, "transactions")# トランザクション形式にする
ap <- apriori(Data4, parameter = list(support = 5/nrow(Data), maxlen = 2, minlen = 2))# 連関規則の作成。
ap_inspect <- inspect(ap)# 連関規則の抽出
ap_inspect$set <- paste(ap_inspect$lhs,"->",ap_inspect$rhs)# 出力用のデータに行を追加
#棒グラフを描くための処理
ap21 <- head(ap_inspect[order(ap_inspect$support, decreasing=T),],20)# support(支持度:同時確率)上位20位までの抽出
ggplot(ap21, aes(x=support, y=reorder(set, support))) + geom_bar(stat = "identity") # 上位20セットの棒グラフを描く
ap22 <- head(ap_inspect[order(ap_inspect$confidence, decreasing=T),],20)# support(確信度:条件付き確率)上位30位までの抽出
ggplot(ap22, aes(x=confidence, y=reorder(set, confidence))) + geom_bar(stat = "identity") # 上位20セットの棒グラフを描く
ap23 <- head(ap_inspect[order(ap_inspect$lift, decreasing=T),],20)# lift(リフト)上位20位までの抽出
ggplot(ap23, aes(x=lift, y=reorder(set, lift))) + geom_bar(stat = "identity") # 上位20セットの棒グラフを描く
#ネットワークグラフ
ap31<- graph.data.frame(ap21[,c(1,3)], directed = F) # グラフ用のデータを作成
plot(ap31) # 支持度のグラフを作成
ap32<- graph.data.frame(ap22[,c(1,3)]) # グラフ用のデータを作成
plot(ap32) # 確信度のグラフを作成
ap33<- graph.data.frame(ap23[,c(1,3)]) # グラフ用のデータを作成
plot(ap33) # リフトのグラフを作成
下のグラフは、いずれも確信度のグラフです。
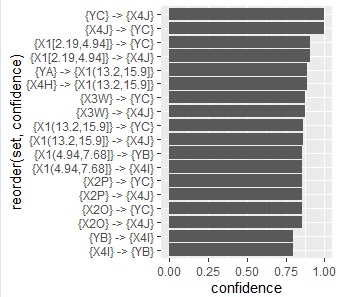
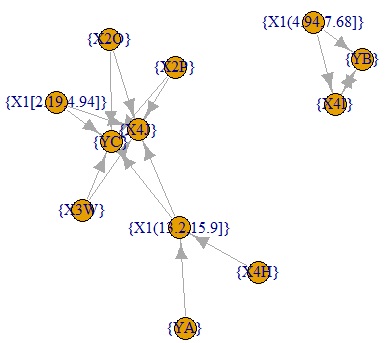
矢印はデータの包含関係を表しているだけで、因果関係は表していません。(
if-thenルールと因果関係の関係
に、この話は詳しくまとめました。)
上のコードでは、下記の考え方でパラメータを設定しました。 ベストかどうかはわかりません。

