 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
教師なし学習 の手法の使い方に、データの類似度の分析があります。 変数の類似度の分析 や、 サンプルの類似度の分析 がよく知られています。
その順番で考えると、カテゴリの類似度の分析は、第3の類似度の分析になります。
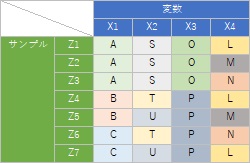
例えば、上のようなデータがあった時に、
X1、X2、等の関係を見るのが、
変数の類似度の分析
です。
Z1、Z2、等の関係を見るのが、
サンプルの類似度の分析
です。
カテゴリの類似度の分析では、「AとSとOの組合せには、関係がありそう」といった見方をします。
質的変数だと、このような分析ができます。
変数の類似度の分析 は、量的変数の関係を調べるものが多いです。 代表的なものが、 相関係数 による分析です。
質的変数は、 ダミー変換 で、量的変数に変換できます。
ダミー変換によって作られたデータについて、 変数の類似度の分析 の方法を使うと、これは、カテゴリの類似度の分析になります。
個々のカテゴリの相関分析 は、そのようにして作られたカテゴリの類似度の分析の方法です。
ラベル分類 の方法を使って、「OKとNGの違いは何か?」という分析をすることがありますが、この時にカテゴリの類似度の分析が役に立ちます。
筆者の場合は、 決定木 と相補的な使い方として、 アソシエーション分析 を使っていました。
アソシエーション分析 は、網羅的にカテゴリの組合せを調べる方法です。
コレスポンデンス分析 は、カテゴリを高次元の座標データに変換して、近さを調べる方法です。
ラフ集合分析 や 質的比較分析(QCA) は、出力が アソシエーション分析 と似ています。
上記の方法だと、同じ特徴のあるカテゴリがある時に、「同じらしい」や「似ている」ということはわかるのですが、それは人が見て判断することになっています。
カテゴリの分解分析 では、カテゴリを要約しますが、計算によって、グループ分けもします。
カテゴリの類似度の分析では、個々のカテゴリの組合せの数を調べます。
このような組合せについて、 テキストマイニングでは、「共起(きょうき)」と呼ばれます。
順路
 次は
カテゴリの相関分析
次は
カテゴリの相関分析
