 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
データサイエンス では、手法の使い道(目的)と、手法の内容のつながりを考えながら使い分ける事が大事なのですが、 とてもわかりにくいです。
手法と目的の関係は、一対一や、一対多ではなく、多対多です。 これが、全体像の理解を難しくしているようです。
特に数理モデルはわかりにくいので、このページでまとめてみました。
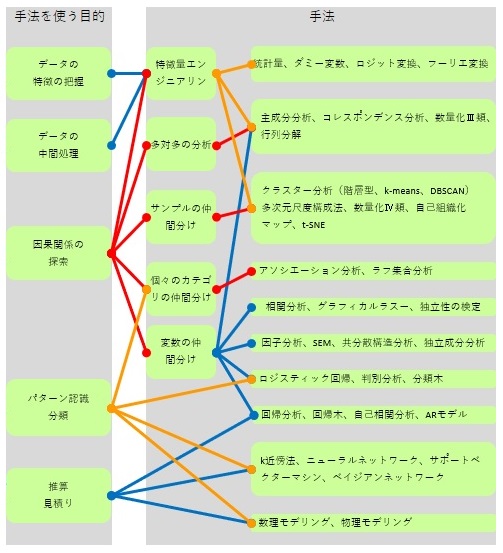
手法と目的の関係は、図のような感じです。
因果関係の探索( 因果推論 )にモデルを使う場合は、モデルの構築の段階で気付いた事が重要です。 データとして持っていない事実にも気付く事があります。 そのため、できた式に含まれる変数や、式の精度はあまり重要ではありません。
「予測・判別」に数理モデルを使う場合は、できた式に値を入力することによって、予測や判別をします。 式の精度(予測精度、的中率、等)は、非常に重要になります。
データ分析の教科書にあるような方法には、コンピュータが手軽に使えない時代に考案され、 コンピュータの普及とともに、一般人でも手軽に使えるようになったものが、数多くあります。
コンピュータの普及直後くらいまでは、一般の人が使うデータは、行も列も大したことがないので、 あまり議論されなかったようですが、現代において、教科書にあるような方法を、教科書通りに使うと問題が起きたり、 期待したことができないことがあります。
例えば、 多次元同時付置図によるコレスポンデンス分析 は、 カテゴリの類似度の分析 に、 高次元を2次元に圧縮して可視化 の方法を使っています。
高次元を2次元に圧縮して可視化 の方法は、 サンプルの類似度の分析 の方法として、よく知られているものです。
それぞれの方法は、よく知られているものですが、組み合わせると単独ではできなかった分析ができるようになるのがポイントです。
統計学の分野では、「 因果推論 」という分野がかなり昔からあります。
「相関関係は因果関係ではない」といった話題がありますが、この分野での議論は伝統的に変数の関係を調べる方法です。 暗黙の内に、「現象の中にある因果関係を明らかにする」という目的が 「変数間の数理的な構造を明らかにする」という話に置き換わって解説されているのが一般的です。
しかし、「変数間の数理的な構造が、知りたい因果関係なのか?」ということがありますし、 「『原因=データの中の何か』と本当に言えるのか?」、という根本的な不明点もあります。
時系列解析 のページに詳しく書いていますが、 伝統的な時系列解析は、 自己相関分析 の理論が中心になっています。
そのため、「この現象は時間的な変化が重要だから、時系列解析」と思って、伝統的な時系列解析の解説を読むと、 知りたいこととのギャップがあります。
順路
 次は
データサイエンスのソフト
次は
データサイエンスのソフト
