 Å@
Å@
 Å@
Å@
Random forest is a decision tree that uses ensemble learning .
A general decision tree tries to make one tree with all the data, but a random forest takes out a part of the data in both rows and columns, makes a tree, and makes multiple trees (forest: forest). We will proceed comprehensively. This will improve overfitting.
There are three main ways to use Random Forest.
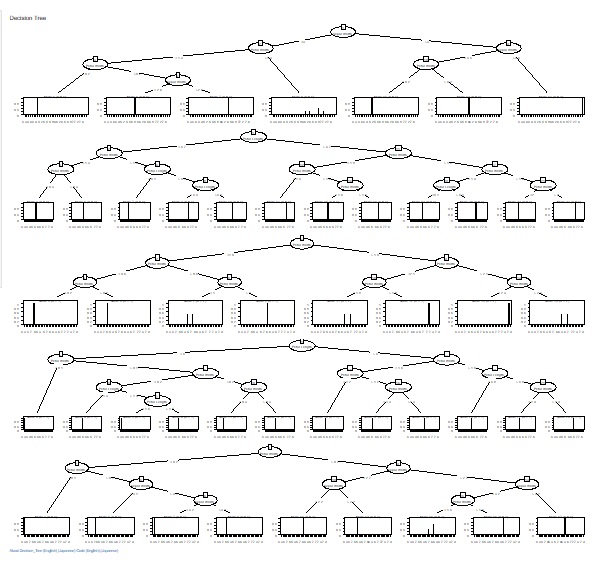
Random forests make many trees and provide comprehensive information. There are various results in the "tree Model" above.
By the way, it seems that there is some information about how each tree was actually made, but it is not output. Therefore, there is a function to output information on the importance of the variable, but I do not understand that "this variable is important because the tree looks like this".
The good thing about decision trees is that they explain the analysis results, which is useful for searching quantitative hypotheses, but not knowing the shape of the tree is the same as making it a black box, so it is a problem. I will end up.
It seems difficult with existing tools, so I've put together the code I wrote for this purpose on the Random Forest page for data analysis .
In addition, as a method just before the random forest, there is a method of making many trees by bagging (extracting only one part of the row), but in the case of bagging, you can see each tree.
The well-known uses of Random Forest are summarized on the Random Forest page. This page is how to use Random Forest to examine the structure of your data. It will be used for data analysis.
This is a way to visually check each random tree made in a random forest.
A typical random forest seems to be a binary tree. However, as I wrote on the N-Shinki page, binary trees are very inconvenient when searching for quantitative hypotheses .
So I also created CHAID-based and C5.0-based random forests.
Examples of R is in the page, Decision tree by R .
R-EDA1 is available.
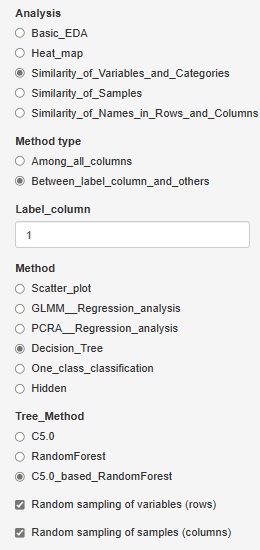
C5.0_based_RandomForest (random forest using C5.0)" was added to "Decision_Tree".
In "C5.0", you can have one tree, but this is made using all variables and all samples.
C5.0_based_RandomForest creates multiple trees by selecting multiple combinations for a part of a variable or sample. This will give you an idea of ??the diversity of your data and the variables that give similar results.
Random sampling is the method of selecting part of the data. I try to choose the number of square roots of the number of rows and columns. For example, for 10000 rows of data, 100 rows will be selected.
If you check "Random sampling of samples (columns)" and uncheck "Random sampling of variables (rows)", you can make multiple trees using one copy of the sample and all the variables. increase. This is a technique called "bagging".
Conversely, if you uncheck "Random sampling of samples (columns)" and check "Random sampling of variables (rows)", multiple trees will use one copy of variables and all samples. To make. This method makes it easier to reach what you want to know when the sample size is small or when analyzing causality.
Å@
Å@
NEXT  Model tree
Model tree
