 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
ランダムフォレストは、 アンサンブル学習 を使う 決定木 です。
アンサンブル学習 を使って、過学習を改善して、ロバストなモデルを作ります。
一般的な 決定木 は、全部のデータで1つの木を作ろうとします。
ランダムフォレストは、行も列も1部のデータを取り出して、木を作ります。 そうした作業を繰り返すと木がたくさんできて、森(フォレスト)になります。
ランダムフォレストの使い方は、大きくは3つに分かれるようです。
アンサンブル学習 の本来の使い方です。 たくさんの木の予測値の平均値を、このモデルの予測値として採用します。
「ロバストなモデルで求めた値」という感じの予測値になります。
因果推論 では 変数の重要度の分析 の方法が重要因子を見つけるのに役立ちますが、その一種としての使い方になります。
この方法は、簡単に言えば、「1番に枝分かれする変数は1点、として、たくさんの木の中での、各変数の平均点を見る方法」と言えるようです。 平均点が一番低い変数ほど、重要な変数と考えます。
ただ、平均値は、データの全体的な傾向の影響を受けるため、ランダムフォレストの結果と、一般的な決定木の結果が変わらないこともあります。
この使い方は、筆者が一番使う使い方ですが、 一般的なランダムフォレストの解説では、紹介されることのない使い方です。
「重要な変数を求める」と使い道が似ているのですが、「重要な変数を求める」と違って、たくさんの木の平均を計算しません。 たくさんの木を「たくさんの仮説」と考えて使う感じになります。
一般的な決定木では、最初に枝分かれする変数は、データ全体の傾向から1種類だけ求まります。 「データが違ったら、 最初に枝分かれする変数はどうなるのか?」ということを、 因果推論 では知りたいのですが、一般的な決定木は、それができる方法になっていません。
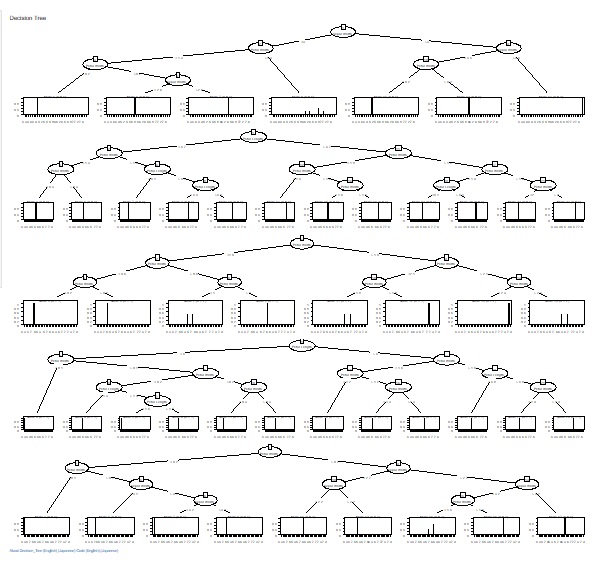
ランダムフォレストで作ったたくさんの木を見ることで、こうしたことが調べられるようになります。
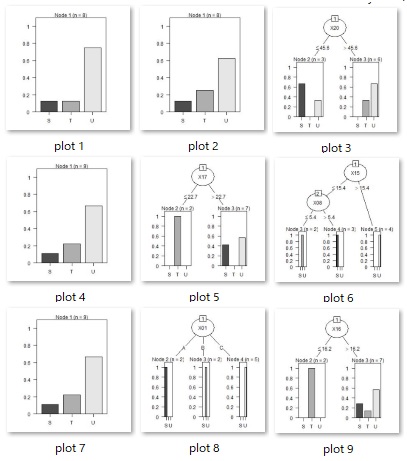
この使い方でも、結論が一般的な決定木の結果と変わらないこともありますが、一番目に枝分かれする変数の候補が複数分かるのが、この方法の良さです。
ランダムフォレストは、有名なので、いろいろなソフトの中に入っています。 ただし、「データの構造を調べる」の使い方ができるものは、限られているようです。
Rによるランダムフォレスト のページにあります。
たくさんの木を表示する機能が入っています。
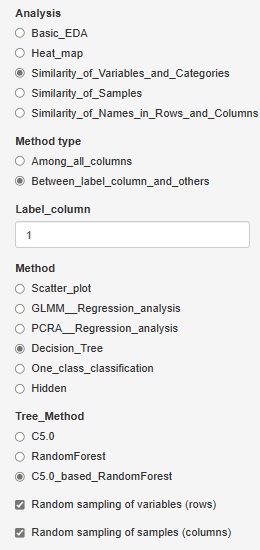
R-EDA1でもランダムフォレストはできます。
「Decision_Tree(決定木)」に、「CART_based_RandomForest(CARTを使ったランダムフォレスト)」と「C5.0_based_RandomForest(C5.0を使ったランダムフォレスト)」があります。
「CART」や「C5.0」では、木は1つできますが、これは全変数、全サンプルを使って作られます。
CART_based_RandomForestと、C5.0_based_RandomForestでは、変数やサンプルの1部について、複数の組合せを選ぶことで、複数の木を作ります。 これによってデータの多様性や、似たような結果になる変数がわかるようになります。
1部のデータの選び方は、ランダムサンプリングです。 行数や列数の平方根の数を選ぶようにしてあります。 例えば、10000行のデータなら、100行が選ばれます。
「Random sampling of samples (columns)」にチェックを入れて、 「Random sampling of variables (rows)」のチェックを外すと、サンプルは1部を使って、変数は全部使う形で、複数の木を作ります。 これは「バギング」という言われている手法になります。
逆に「Random sampling of samples (columns)」のチェックを外して、 「Random sampling of variables (rows)」にチェックを入れると、変数は1部を使って、サンプルは全部使う形で、複数の木を作ります。 サンプル数が少ない場合や、因果関係の分析では、このやり方の方が知りたいことに到達しやすくなります。
同志社大学 金明哲先生のページ
Rと集団学習
https://www1.doshisha.ac.jp/~mjin/R/Chap_32/32.html
順路
 次は
モデル木
次は
モデル木
