 僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 | ENGLISH
乽Y偑侾屄偱丄X偑暋悢偩偐傜 廳夞婣暘愅 傪巊偍偆丅乿偲偄偆偙偲偱丄廳夞婣暘愅傪巊偭偰傒偰傕丄 弌偣傞寢壥偑丄 扨夞婣暘愅 偲曄傢傜側偄偙偲偼丄傛偔偁傝傑偡丅
扨夞婣暘愅偺寢壥偲摨偠帪偲堘偆帪偼丄偳傫側帪側偺偐傪抦偭偰偄傞偲丄 寢壥偺尒曽傗尒偣曽偺栶偵棫偪傑偡丅
壓偺恾偺尒曽偱偡偑丄Y偑栚揑曄悢丄X1丄X2偑愢柧曄悢偱偡丅 F1丄F2偲偄偆偺偼丄 場巕暘愅 偱愽嵼曄悢偲屇偽傟偰偄傞傕偺偱丄僨乕僞偲偟偰偼帩偭偰偄側偄偗傟偳傕丄偦偺僨乕僞偺憹尭偺尨場偵側偭偰偄傞場巕偱偡丅
場壥娭學偲偟偰偼丄X1偲Y偵場壥娭學偑偁傝丄X2偲Y偵偼側偐偭偨偲偟偰傕丄X1偲X2偺場巕偑嫟捠偺応崌偱偡丅
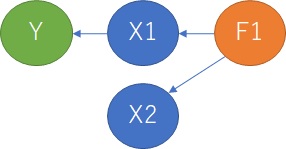
偙偺応崌丄扨夞婣暘愅偱偼丄X1偲Y偺憡娭偑崅偔側傞偩偗偱側偔丄X2偲Y偺憡娭傕崅偔側傞偙偲偑偁傝丄 杮摉偺場壥娭學偑丄偳偪傜偵偁傞偺偐偼丄僨乕僞偩偗偱偼敾抐偡傞偙偲偑擄偟偄偱偡丅 憡娭學悢偺戝偒偝偱丄偳偪傜偵偁傞偺偐傪寛傔傞偙偲偼偱偒傑偡偑丄 乽偙偺僨乕僞偩偲丄偦偆偐傕偟傟側偄偑丄偄偮傕偦偆側傞偐偼傢偐傜側偄乿偲偄偆媈擮偑巆傝傑偡丅
廳夞婣暘愅偱傕丄 曄悢偺慖戰 偺曽朄傪巊偭偰丄X1偲Y偩偗傪巊偭偨儌僨儖傪嶌傟傞偐傕偟傟傑偣傫偑丄僨乕僞偵傛偭偰偼丄X2偲Y偺儌僨儖偑摫偐傟傞偐傕偟傟傑偣傫丅
媅帡憡娭
偑偁傞応崌偱偡丅
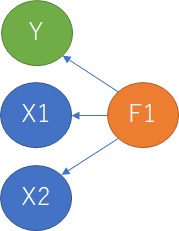
扨夞婣暘愅偱偼丄Y偲X01丄Y偲X02偺慻崌偣偺偦傟偧傟偵偮偄偰丄儌僨儖偑嶌傟傑偡丅
廳夞婣暘愅偱傕丄Y偲偳偺X傪慻傒崌傢偣偰傕丄偁傑傝曄傢傜側偄儌僨儖偵側傝傑偡丅
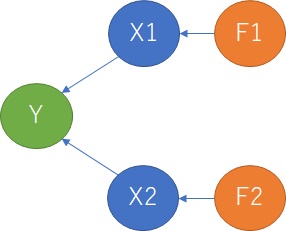
俀偮偺X偺場巕偑丄偦傟偧傟堎側傝丄Y偼X偺慄宍榓偵側偭偰偄傞応崌偱偡丅
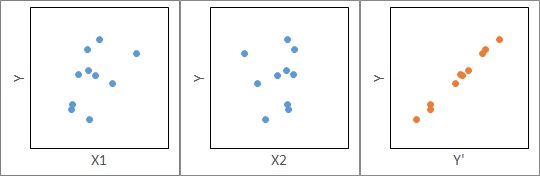
偙偺応崌丄椺偊偽丄壓恾偺傛偆偵X1偲Y丄X2偲Y偺慻崌偣偱嶶晍恾傪尒傞偲丄偄偢傟傕憡娭偑偁傞傛偆偵偼尒偊側偄偙偲偑偁傝傑偡丅
廳夞婣暘愅偱儌僨儖傪嶌偭偰丄夞婣幃偱Y偺悇掕抣偺Y'傪寁嶼偡傞偲丄Y偲Y'偵偼旕忢偵崅偄憡娭偑弌偰棃傞偙偲偑偁傝傑偡丅
偙偺応崌偼丄扨夞婣暘愅偩偗偩偲丄乽Y偲X偵偼娭學偑側偄乿偲偄偆寢榑偵側傝傑偡偑丄廳夞婣暘愅偩偲乽Y偲X偵偼娭學偑偁傞乿偲偄偆寢榑偵側傝丄
尰徾偺儊僇僯僘儉偺夝柧偑恑傒傑偡丅
X偑俀偮偱丄場巕偑俀偮側偺偼丄偙偺慜偺働乕僗偲摨偠偱偡偑丄偦傟偧傟偺X偼丄F1偲F2偺慄宍榓偵側偭偰偄傞応崌偱偡丅
傑偨丄Y偼F偺曅曽偲偩偗場壥娭學偑偁傞傕偺偺丄X偲偼場壥娭學偑側偄偱偡丅
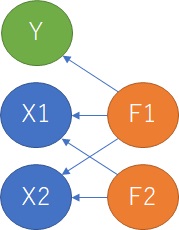
偙偺応崌傕丄X1偲Y丄X2偲Y偺慻崌偣偱嶶晍恾傪尒傞偲丄偄偢傟傕憡娭偑偁傞傛偆偵偼尒偊側偄偙偲偑偁傝傑偡丅
傑偨丄扨夞婣暘愅偲廳夞婣暘愅偱寢榑偑堎側傞揰傕摨偠偱偡丅
偟偐偟丄X偺攚屻偵偁傞儊僇僯僘儉偑丄乽俀偮偺X偺場巕偑丄偦傟偧傟堎側傞応崌乿偲偼堘偄傑偡丅
偙偺応崌丄F1偺塭嬁偑X偵戝偒偔弌偰偄傞偲丄Y偲X1傗丄Y偲X2偺憡娭偼崅偔尒偊傞傛偆偵側傞偨傔丄忋婰偺媈帡憡娭偺応崌偲偁傑傝曄傢傜側偄暘愅偵側傝傑偡丅
峫嶡偑擄偟偔側傞偺偼丄F1偺塭嬁偑X偵懳偟偰彫偝偔丄F1偑 塀傟曄悢 偵側偭偰偄傞応崌偱偡丅
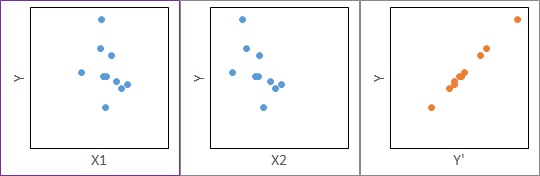
偙偺応崌丄廳夞婣暘愅偺寢壥偑丄乽俀偮偺X偺椉曽偑Y偵塭嬁偟偰偄傞乿偲側傞揰偼丄 乽俀偮偺X偺場巕偑丄偦傟偧傟堎側傞応崌乿偲摨偠偱偡丅 偦偺偨傔丄乽俀偮偺X偺場巕偑丄偦傟偧傟堎側傞応崌乿偺傛偆偵夝庍偝傟傗偡偄偱偡丅
乽俀偮偺X偺場巕偺偦傟偧傟偑丄俀偮偺場巕偺塭嬁傪庴偗偰偄傞応崌乿偩偲婥偑晅偔偵偼丄廳夞婣幃偺學悢偺抣傗晞崋傪妋擣偡傞昁梫偑偁傝傑偡丅 乽學悢偺愨懳抣偑丄傎傏摨偠側偺偼丄側偤丠乿傗丄乽偙偺晞崋偼丄側偤儅僀僫僗丠乿偲偄偆偙偲偱婥晅偗傞偙偲偑偁傝傑偡丅
F1偺塭嬁偑X偵懳偟偰彫偝偄帪偼丄學悢傪挷惍偟偰丄X1偲X2偵娷傑傟偰偄傞F2偺塭嬁傪憡嶦偝偣傞偙偲偱丄Y乫偺拞偵F1偺塭嬁偩偗偑巆傞傛偆側寁嶼偵側傝傑偡丅 偙偆偡傞偙偲偱丄Y乫偲Y偺憡娭偑崅偔側傝傑偡丅
弴楬
 師偼
晞崋斀揮
師偼
晞崋斀揮
