 R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
暘妱昞 傪僗僞乕僩偵偡傞 僐儗僗億儞僨儞僗暘愅 偺幚巤椺偱偡丅
幙揑曄悢傪僗僞乕僩偵偡傞僐儗僗億儞僨儞僗暘愅偼丄 R偵傛傞幙揑曄悢偺僐儗僗億儞僨儞僗暘愅 偵偁傝傑偡丅
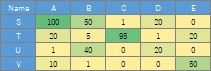
昞偺抣偼丄昿搙傗娭學偺嫮偝傪昞偟偰偄偰丄戝偒偄傎偳娭學偑嫮偄応崌偱偡丅
侽偑堦斣彫偝側抣偱丄乽娭學側偟乿偺堄枴偵側偭偰偄傞偲偟傑偡丅
壓婰偺僨乕僞偺応崌偼丄B偲T偑堦斣嫮偄娭學傪昞偟偰偄傞偲偟傑偡丅
僐乕僪偺椺偱偼丄堦斣嵍偺楍偼僒儞僾儖柤偲偟偰巊傢傟傑偡丅
僨乕僞偑侽埲忋偺惍悢偺帪偵巊偊傞曽朄偱偡丅 椺偊偽丄昿搙偺帪偼巊偊傑偡丅
僐儗僗億儞僨儞僗暘愅
偺弌椡傪
懡師尦広搙峔惉朄
偱張棟偟偰
懡師尦摨帪晅抲恾
傪嶌傞曽朄偱偡丅
僐儗僗億儞僨儞僗暘愅偺寢壥偑懡師尦偵側偭偰偄傞応崌偼丄晛捠偺摨帪晅抲恾偱偼丄暘愅偱娫堘偄偑婲偒傞壜擻惈偑偁傞偺偱丄
偙偺曽朄傪巊偆偲曋棙偱偡丅
library(MASS) # 僷僢働乕僕傪撉傒崬傒
setwd("C:/Rtest") # 嶌嬈梡僨傿儗僋僩儕傪曄峏
Data <- read.csv("Data.csv", header=T, row.names=1) # 僨乕僞傪撉傒崬傒
pc <- corresp(Data,nf=min(ncol(Data),nrow(Data))) # 僐儗僗億儞僨儞僗暘愅
pc1 <- pc$cscore # 僗僐傾傪撉傒庢傝
pc1 <- transform(pc1 ,name1 = rownames(pc1), Group = "A")# 峴柤傪捛壛
pc2 <- pc$rscore # 僗僐傾傪撉傒庢傝
pc2 <- transform(pc2 ,name1 = rownames(pc2), Group = "B")# 楍柤傪捛壛
Data1 <- rbind(pc1,pc2)# 僨乕僞傪寢崌
round(pc$cor^2/sum(pc$cor^2),2)# 婑梌棪傪媮傔傞丅
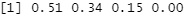
# 忋婰偺寢壥偐傜丄俁斣栚傑偱偺屌桳抣偼婑梌棪偑崅偄偙偲偑傢偐偭偨偺偱丄偙偺屻偺夝愅偵偄傟傞偙偲偵偟傑偡丅
# 偪側傒偵丄婑梌棪偺掅偄偲偙傠傪擖傟傞偲丄偦傟偑僲僀僘偵側傞傜偟偔丄偒傟偄偵暘棧偝傟側偔側傝傑偡丅
MaxN = 3# 巊梡偡傞屌桳抣偺悢傪巜掕
Data11 <- Data1[,1:MaxN]# 崁栚偺偁傞楍傪巜掕
Data11_dist <- dist(Data11)# 僒儞僾儖娫偺嫍棧傪寁嶼
sn <- sammon(Data11_dist) # 懡師尦広搙峔惉朄
output <- sn$points# 摼傜傟偨2師尦僨乕僞偺拪弌
Data2 <- cbind(output, Data1)丂 # 尦僨乕僞偲懡師尦広搙峔惉朄偺寢壥傪崌傢偣傞丅
library(ggplot2) # 僷僢働乕僕偺撉傒崬傒#
ggplot(Data2, aes(x=Data2[,1], y=Data2[,2],label=name1)) + geom_text(aes(colour=Group)) # Name傪巊偭偨尵梩偺嶶晍恾
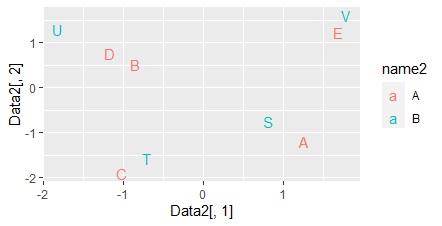
昞偺抣偼丄幙揑僨乕僞偺応崌偱偡丅
幙揑暘妱昞偺僐儗僗億儞僨儞僗暘愅
偺椺偱偡丅

偄偢傟偺曽朄傕丄峴偺崁栚柤偑侾楍栚丄楍偺崁栚偑俀楍栚丄抣偑俁楍栚偵側傞傛偆偵僨乕僞傪暲傋曄偊偰偐傜巊偄傑偡丅
library(tidyr) # 儔僀僽儔儕偺撉傒崬傒
library(dplyr) # 儔僀僽儔儕偺撉傒崬傒
library(fastDummies) # 儔僀僽儔儕偺撉傒崬傒
library(MASS) # 儔僀僽儔儕偺撉傒崬傒
library(ggplot2) # 儔僀僽儔儕偺撉傒崬傒#
setwd("C:/Rtest") # 嶌嬈梡僨傿儗僋僩儕傪曄峏
Data <- read.csv("Data.csv", header=T) # 僨乕僞傪撉傒崬傒
Data1 <- tidyr::gather(Data, key="Group", value = Val, -Name) # 廲宆偵曄姺乮Name偺楍埲奜傪愊傒忋偘傞乯
Data_dmy <- dummy_cols(Data1,remove_first_dummy = FALSE,remove_selected_columns = TRUE)# 僟儈乕曄姺
pc <- corresp(Data_dmy,nf=min(ncol(Data_dmy))) # 僐儗僗億儞僨儞僗暘愅
pc1 <- pc$cscore #
pc1 <- transform(pc1 ,name1 = rownames(pc1))# 峴柤傪捛壛
round(pc$cor^2/sum(pc$cor^2),2)# 婑梌棪傪媮傔傞丅
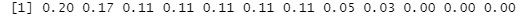
# 忋偺椺偱偼丄俋斣栚埲崀偺屌桳抣偼婑梌棪偑掅偄偺偱丄偙偺屻偺夝愅偐傜奜偡偙偲偵偟傑偡丅
MaxN = 8# 巊梡偡傞屌桳抣偺悢傪巜掕
Data11 <- pc1[,1:MaxN]# 崁栚偺偁傞楍傪巜掕
Data11_dist <- dist(Data11)# 僒儞僾儖娫偺嫍棧傪寁嶼
sn <- sammon(Data11_dist) # 懡師尦広搙峔惉朄
output <- sn$points# 摼傜傟偨2師尦僨乕僞偺拪弌
Data2 <- cbind(output, pc1)丂 # 尦僨乕僞偲懡師尦広搙峔惉朄偺寢壥傪崌傢偣傞丅
ggplot(Data2, aes(x=Data2[,1], y=Data2[,2],label=name1)) + geom_text() # Name傪巊偭偨尵梩偺嶶晍恾
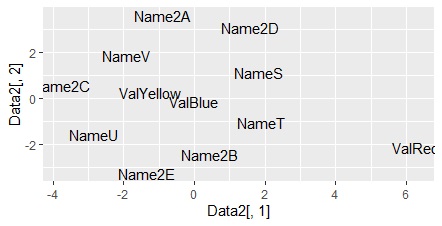
偙傟傕丄夝庍偟偵偔偄偱偡偑丄偲傝偁偊偢僨乕僞偑僌儔僼偵側傝傑偟偨丅
Red偑奜傟偨偲偙傠偵攝抲偝傟傞偺偼丄忋偺曽朄偲摨偠偵側傝傑偟偨丅
