 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
学問の世界には、「不可能」ということを示す理論がいろいろと発見されて来て、そういう事をまとめた本もあります。
データには、「記号を使っている」という側面と、「認識や測定を通して得られている」という側面があります。
どちらの側面に対しても不可能の理論があり、
データサイエンス
を進める上で、どこかで意識しておいた方が良い内容になっています。
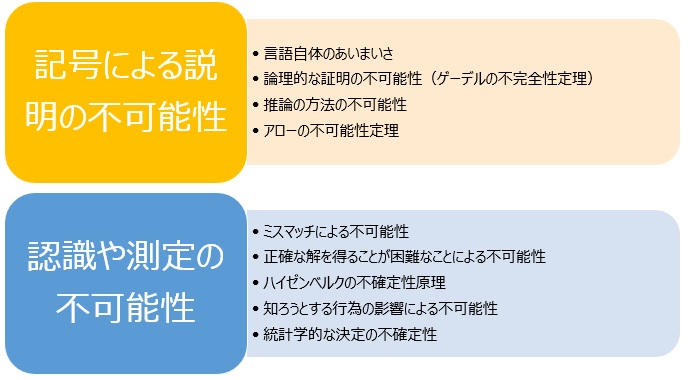
記号学 、 哲学 、 言語学 では、同じ単語でも、人によって意味が違う事や、同じ人でも時と場合によって意味が違う事、 定義したとしても、単語の説明を別の単語でするだけなので、意味を固定できない事が言われています。
完璧な説明をするために必要な「言語」というものにはあいまいさがあり、言語を使う以上は完璧な説明はできないです。
論理学 の理論です。 完璧のように見える論理の世界ですが、実はそうではないことを示しています。
記号だけで議論するようにすれば、言語のあいまいさを避けることができますが、 そうだとしても、無理があることを示しています。
論理的推論 のうち、演繹法以外では、論理の飛躍があります。 例えば、帰納法では、いくつかの事実を集め、それを根拠にして、「だからこうです」という推論をしますが、ここで飛躍があります。
日常生活では、こういう飛躍を頻繁に使って 認知と学習 が進んでいます。
しかし、限られた個数の事実による結論なので、「その事実と異なる例は、本当にないのか?」と言われてしまうと、それは誰にもわからないです。 「誰にもわからないのなら、証明したことにはならない」と言われてしまえば、そうなのですが、 その主張を始めると、いつまでも前に進めなくなります。 ビジネスの場では、わからないことはリスクとしておいて、わかっていることで前に進むのが、得策になります。
社会学 の理論です。 もともとは、完璧な民主主義を定義すると、それが可能な選挙の方法はないことの証明になっています。
「 ダークデータ 」という名前で言われている正体不明のデータがあります。
「データには宝が隠されている。だから、データから宝を掘り出すのだ」といった感じで、データに期待が寄せられることがありますが、 本当にそうなのかは、わかりません。
1mm幅の定規で、原子のように小さなものの大きさは 測定 できません。 また、月までの距離のような大きなものも測定できません。
このように、その測定システムが想定している範囲以外のものは、測定できないという不可能性があります。
人間の五感で感じられることの性質や速さにも、人間という測定システムの限界があります。 ただし、人間の仕組みはわかっていないことがたくさんあるので、不可能と言われていた説が変わることもあるようです。
測定方法のミスマッチは、データを得る前の話ですが、こちらは、データを得た後の話です。
「 因果推論 」、「 時系列解析 」、「 品質工学 」といった分野があります。
詳しくは、このサイトのそれぞれの項目で解説していますが、 例えば、学問としての因果推論は、「因果関係があれば、データはこういう構造になる」ということを定義して、 その範囲で成り立っている学問になっています。 そのため、「因果推論」という分野を勉強しても、どうにもならない因果関係の問題は、世の中にたくさんあります。 同様のことが、時系列解析や品質工学でも起きます。
筆者の経験の範囲では、自分が扱おうとしている「因果」、「時系列」、「品質」と、既存の学問が合っていないことは、よくあります。
複雑系 では、決定論に従うモデルであっても、確定的な予測ができないことが示されています。 身近な例は天気予報です。
決定論のモデルなので、シミュレーションで未来を予測することはできるのですが、 初期値がちょっと変わっただけで、結果が大きく変わってしまいます。 例えば、初期値が10.001と10.002と10.003で、結果が変わってしまうようなことが起きます。 この例の場合だと、5桁目が違うだけですが、一般的な測定で、5桁目が正確に把握できることはないです。 そのため、初期値が決められず、予測ができないです。 また、こういう不安定な系では、仮に初期値が細かく把握できていたとしても、途中の計算がどこまで精度良くできるのかがわからず、 予測の結果は信頼ができないものになります。
量子物理学という物質のミクロな状態を研究する分野の理論です。 日常では、位置と速度は確定的なものですが、電子に対しては、そのような扱いができないことを示しています。
物理学的には、電子のこのような性質をどのように記述するのかや、どのように応用するのか、といったことがポイントになります。
不確定性原理は、物理学以外でとても有名になっているのですが、日常的な感覚と合わないことが根本的な原因のようです。 そのギャップを埋めるために、いろいろな話が登場しています。
測定によって得られたもの、つまりデータは「測られたものの、そのものを表している」と思われています。 例えば、定規で長さを測っている時は、得られた「〇〇mm」というデータは、確かにその長さの物を測っています。
ところが、そうではないことがあり、「測定」という行為自体の影響を受けていることがあります。 例えば、 アンケート では、質問の順番や、質問の言葉の使い方によって、回答が変わってしまいます。 また、物理的な測定では、見るために使った光によって、測られるものに変化が起きてしまい、見ている時に起きていることと、 見ていない時に起きていることが違うこともあります。
不確定性原理が書かれている文献の中で、「不確定なのは、測定する行為の影響を受けるから」という説明がされることがありますが、 不確定性原理は、測られるもの自体がそもそも不確定な性質を持っているということなので、測定の影響の話とは異なります。
統計学 では、たくさんの物を全体的に見ようとすると、 正規分布 のような扱いができるという性質を扱います。 いったん、分布を仮定すると、どの値になるのかは、確率的なものと考えます。 ポイントは、1回1回は決定論に従って値が決まっているけれども、そういう現象全体を扱う時には、確率を使って表現している点です。
例えば、「サイコロの目は、6分の1の確率」と考えられるようになります。
統計的に物事を扱おうとすると、分布によるばらつきが不確定な要素になります。
不確定性原理の理解として、決定論に従っているものを確率的なものとして考える事と、「ひとつの電子自体が広がりを持った存在になっている」という事が混同されていることがあるようです。
不可能の理論は、 アナロジー で想像を広げて、まったく別の分野に当てはめてみると、その分野の新しい切り口になります。
ただし、不可能の理論は、ある条件や言葉の定義の中で成り立っているものなので、 条件を無視して、象徴的な表現だけを抜き出し、それが万物の真理のように語る進め方は乱用です。 また、条件を一致させたとしても、別の分野でも「不可能」となるかどうかはわからないです。
そのため、別の分野での仮説として書くのは良いかもしれませんが、「不可能な事は証明されている」といった書き方は行き過ぎです。 科学論のような説明の中で、このような行き過ぎを、時々見かけます。
ハイゼンベルクの不確定性原理は、量子力学の本では必ず出て来るような有名な話です。 ゲーデルの不完全性定理は、 論理学 の入門書では、一番最後の方で、紹介されることが多いです。 アローの不可能性定理は、 ゲーム理論 の中で紹介されることがあります。
不可能の理論は、その分野が一通り説明された後で、例外的な存在として説明されることが一般的ですが、 下記の参考文献では、「世の中には不可能なことがある」ということを中心にした内容になっています。
「感性の限界 不合理性・不自由性・不条理性」 高橋昌一郎 著 講談社 2012
・行為の限界 : 行動科学的な限界。
心の動きががあって、行動していると考えているのではなく、状況に対して体が反応しているだけがある。
行動経済学によって、人は事前情報があると、それを使って合理的な結論を出してしまうクセがあることがわかっている。
・意志の限界 : 環境や遺伝子によって、完全に自由な意志はない。決定論があるが、そうではないこともあるので、そこは自由意志の余地になる。
・存在の限界 : 死、自殺、責任、科学、テロリズム、戦争、等について、それらは何なのか、ということの様々な説を紹介。
「知性の限界 不可測性・不確実性・不可知性」 高橋昌一郎 著 講談社 2010
・言語の限界 : 前期のウィトゲンシュタインは、哲学的な問題は、言語のあいまいさに起因する問題のため、議論が無意味とした。
後期のウィトゲンシュタインは、言語はあいまいだが、それを使って文化が成り立っていることに注目。
・予測の限界 : 予測の方法に帰納法があるが、帰納法には反例が入る余地があるため、予測の方法として完璧ではない。
複雑系は予測ができない。
・思考の限界 : 神や宇宙については様々な説明があるが、万人が納得できるようなものはない。
(この章は、言語の限界の後に来ますが、言語の限界の話はないような形で議論が進んでいます。)
「理性の限界 不可能性・不確定性・不完全性」 高橋昌一郎 著 講談社 2008
・選択の限界 : アロウの不可能性定理では、完全な民主主義を定義した時に、それを成立させられないことが証明された。
その他、囚人のジレンマ等で、自分の利得と、他人の利得の両立のさせ方が問題視されている。
・科学の限界 : ハイゼンベルクの不確定性原理。すべての原子の位置と速度がわかれば、ニュートン力学によって、未来が予測できると考えられる説が間違いであることがわかった。
・知識の限界 : ゲーデルの不完全性定理。あらゆる命題は真か偽のいずれかで、それらは必ず証明か反証ができる、という考えは間違い。
「不可能、不確定、不完全 「できない」を証明する数学の力」 ジェイムズ・D.スタイン 著 早川書房 2011
原著は、「How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern Physics」です。
ハイゼンベルクの不確定性原理、ゲーデルの不完全性定理、アローの不可能性定理の3つを、ビッグスリーと呼んでいます。
これらを頂点のようにして、その他にも不可能な問題を紹介しています。
また、これらの問題の周辺にある数学や、人の動きも紹介しています。
スケジューリング問題 : 必ず最短の合計時間になるアルゴリズムはない。評価指標によって、最適解は変わる。
プログラムの無限ループ問題
順路
 次は
データサイエンスの流派
次は
データサイエンスの流派
