 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
いろいろな分野や立場の人の書いたものを読んだり、お話を聞いていると、「データ分析の仕事」はいろいろです。 筆者は、仕事でデータ分析に関わって約20年になりますが、筆者自身も、いろいろな形のデータ分析をしたことがあります。
広い意味で「データ」を使う点は同じなのですが、データベースにある数字のデータのこともありますし、 頭の中にある情報をデータとして使うこともあります。 数字のデータだとしても、目的やゴール、そのためにやることは、いろいろです。
どういう種類があるのかを、まとめてみました。
なお、このページは、筆者のこれまでの記憶を元にしてまとめています。 世の中には、このページにはない形のデータ分析の仕事があるかもしれず、もしも、そういったものが今後見つかれば、追加します。 また、文中の「多い・少ない」という表現は、あくまで筆者の経験の範囲の話です。
データ分析の解説では、テーブルデータがある状態から話が始まることが多いです。
一方、実務の中でデータ分析をする時は、分析対象のデータがないところからの方が、普通です。
データ分析が誰かに頼まれて始まることは、少ないです。
例えば、品質管理、生産管理、マーケティングなどが本業の人は、自分の本業の中でデータ分析をします。 そういう場合は、本業を進める流れの中で、データ分析が始まります。
その場合、どんなデータ分析をするのかから、自分で考える必要があります。

データ分析をする時に、データ分析用のデータが前もって用意されているとは限りません。
データベースや、インターネット上のどこかにあるのなら、それを探して使うこともできますが、世の中のどこにもないデータが必要になることもあります。
データ分析に使うデータを、データ分析をする人が作ったり、 測定 して用意できると、データ分析でできることが格段に増えます。 また、測定の中でデータ分析の知識があると、質の良いデータが集められます。
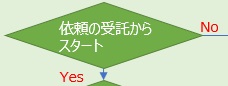
図に示している順番は、望ましい順番です。
例えば、「システムを作る」までには長い道のりがありますが、時と場合によっては、段階を飛ばしてシステムを作り始めることもあります。

依頼者のニーズに応じて、データを集計して報告する仕事が、世の中にはあります。
そういう仕事の場合は、データを自在に抽出したり加工したりすることが、誰かの役に立っています。
これだけでも、SQLの知識が必要だったりして、誰でもできるものではないことがあります。
また、例えば、「1年間の売上の推移のグラフが欲しい」という依頼なら、 データ分析者のアイディアは不要かもしれませんが、たくさんのグラフを作ったり、グラフ同士の関係も知りたいような分析では、 分析者の結果の見せ方で意思決定が変わることもありますので、分析者のアイディアが重要になります。

データ分析の解説では、「データは宝の山で、宝を見つけるのがデータ分析の仕事」という表現がされることがあります。
しかし、データ分析で、「これとこれは相関がある。これとこれは相関がない。」、「こういうパターンが時々起きる」、といったことがわかったとしても、 「有益」とならないことが多いです。 「データ分析者は初めて知った事だが、そのデータに普段関わった仕事をしている人にとっては、常識だった。」という状況は、 データ分析を専門にする立場で仕事をした人から、よく聞く話です。(筆者にも経験があります。)
こういう状況は、データにデータ分析の手法を当てはめて、結果をまとめただけの時によく起きます。
有益な情報は、データの背景をよく知っている人が自分でデータ分析をするか、 そうした人と、データの集計や可視化の方法をいろいろ知っている人が協力して進めるのが、一番効率的に導き出せるようです。 このような進め方をした時には、データを集計して実態をグラフなどで見える形にするだけでも、意味があることがあります。 例えば、「このパターンは、滅多にないと思っていたけど、意外と多い」などです。

例えば、データ分析の結果、不良品を発生させてしまう原因がわかったのなら、原因が発生しないようにすれば、解決します。
このような場合は、データの継続的な活用を考える必要はないです。
データ分析の解説では、解決手段もデータの話になっていて、 システムを作ったり、ビジネスモデルを作ったりして、データを継続して使い続けることがデータ分析の後ろの方で出て来ることがありますが、 実際は、そうした進め方が適切ではない場合もたくさんあります。
データサイエンスの仕事
のページにもありますが、機械学習のモデルを作ることに意味のあるデータ分析は、データ分析全体のケースの中では、少ない方です。
ビジネスモデル によっては、システムを作ることがあっても、機械学習のモデルは使わないことがあり、 そうだとしても、 デジタルトランスフォーメーション(DX) になることもあります。

ここでは仕事としてのデータ分析なので、終わりは「分析結果を報告」になります。
報告の相手は、上司、別の部署、依頼主の企業、等になります。
ここにつながって来るものは、様々なルートがあります。 例えば、「データを集計して終わり」と、「システムを作って終わり」では、だいぶ違う話になりますが、 それで良いのかどうかは、そのデータ分析の目的次第です。 集計されたデータを欲しい人がいるのなら、集計すれば終わりになります。 次のアクションの提案をするところまでが「分析結果」なら、そこまで進めて報告です。 提案を実行した結果までが、報告に必要なこともあります。
データ分析をプロジェクトで進める場合について書かれている文献は、 プロジェクトマネジメント のページにあります。
「文系でも数式なしのPython×Excelで稼ぐ力を上げる!」 日比野新 著 かんき出版 2021
ECサイトの販売戦略の分析が中心です。
簡単なグラフが中心です。
少し進んだものとして重回帰分析や、数量化
もあります。ほとんどの内容は、ExcelでもPythonでも似た結果が出せるものです。
最後の方にある顔の画像の分類だけが、Pythonでしかできない高度な内容になっています。
異なるサイズの画像の大きさを合わせたり、画像を
k平均法
で分類する方法が紹介されています。
キャスティング分析、というそうで、ここだけがPythonでないとできない部分です。
しがらみのあるような会社でデータ分析の活用を始める時は、最初はコストダウンを目的にすると良い。
データ分析をした結果を話す時は、具体的なお金の金額を出すと、わかりやすく、反論されにくい。
折れ線グラフ、ヒストグラム、散布図を使って、「〇〇は良くなっている」、「〇〇が上がれば、××が下がる」というように、
従来は言葉だけで語られていた内容を、グラフにしてみると、それが本当かどうかや、どの程度起きているのかが議論できるようになる。
「データ分析力を育てる教室」 松本健太郎 著 マイナビ出版 2022
著者が、データ分析の仕事を始めた当初は、データの数字だけを見るような分析だったため、顧客の期待に応える形にならなかったそうです。
その経験から、「仮説を立てて、仮説を検証する」という形のデータ分析に行き着いたそうです。
「Python実践データ分析100本ノック」 下山輝昌・松田雄馬・三木孝行 著 秀和システム 2022
顧客から「データ分析を使って業務を改善できないか」という依頼を受けたところからスタートになっています。
綺麗ではないデータを処理するところからです。
売上の集計、顧客の行動分析、物流のルート最適化問題で、データ分析で即戦力になるとしています。
それに加えて、画像処理や、自然言語処理も紹介しています。
「社内外に眠るデータをどう生かすか データに意味を見出す着眼点」 蛭川速 著 宣伝会議 2018
マーケティング
として、新商品の企画をするまでの流れを説明しています。
プロセスは、大きく分けて3段階です。
・現状把握:市場規模の推移、顧客・生活者の実態と意識、競合企業の状況
・仮説設定:ターゲット設定、ベンチマーク商品の成功要因分析、ニーズ仮説の抽出、アイデア発想
・企画立案:仮説検証(アンケート調査)、ビジネスモデル、コンセプトシート、売上予測
アンケート以外は、必要なデータをインターネットで検索して集める方法になっています。
ネット上の情報は、玉石混交なので、Fact(事実)を表している情報を重視すると良いそうです。
数値のデータなどになります。
統計分析から導くと良い指標として、構成比、代表値、増減率の3つを挙げています。
「ビジネスデータアナリティクス・ガイド」 IIBA日本支部『ビジネスデータアナリティクス・ガイドv1』翻訳プロジェクト 翻訳 IIBA日本支部 2022
ビジネス関係のデータ分析を進める時の、基本的な手順がまとまっています。
いろいろな分析手法の簡単な説明はありますが、分析の具体的な内容はありません。
「AI・データ分析モデルのレシピ」 漆畑充 編著 オーム社 2021
「顧客データ × クラスタリング分析モデル」、「広告効果データ × 重回帰分析モデル」、「キャンペーンデータ × ロジスティック回帰分析モデル」、「調査データ × コレスポンデンス分析モデル」、「Eコマースデータ × 協調フィルタリング分析モデル」という風にして、
データと適した手法の組合せで解説しています。
「データ分析のための機械学習入門」 橋本泰一 著 SBクリエイティブ 2017
LINE社の方の本です。
そのためだと思いますが、機械学習の話だけでなく、HADOOPなどの分散処理や、
リアルタイム分析にどのようなものがあるのか、といった話にもページを割いています。
順路
 次は
データ分析の基本
次は
データ分析の基本

