One-Class Model is used as Model of Outlier .
Two-Class Model is more famous than One-Class Model. Discriminant Analysis , Logistic Regression Analysis and Support Vector Machine are examples of two- class model.
These methods are used to judge the class in two.
One-Class Model is made only majority side data.
This idea is not new because same idea is used in Hypothesis Testing .
Logic is that "If it is not judged in the side of majority, it is the side of outliers."
One-Class model solves the problems ot Two-Class Model.
One-Class SVM and One-Class Minimum distance method are one of the One-Class Model.
And model of Non-Supervised Learning is also used. For example, Principal Component Analysis .
When we make one-class model, we do not need the variable of labels. It is the same way of non-Supervised Learning. So we can use non-Supervised Learning as the model of one-class model.
We use the variable of labels, when we use the model.
We can make the model without the outlier data. But if we have the outlier data, it can be used to check the performance of the model.
MT method is classical one-class model.
The simplest one-class model is using normal distribution of one variable. MT method uses the multidimensional normal distribution.
MT method uses the outlier data for Selection of Variables .
The idea of one-class model is also used if Y is quantitative variable.
For example, this idea is used to estimate the value of abnormal case by Regression Analysis .
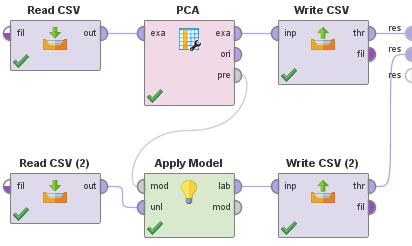
The way to use software for one-class model is similar in the page, Software for Prediction .
This exapmle uses Principal Component Analysis .
setwd("C:/Rtest") # Change directory
Data1 <- read.table("Data1.csv", header=T, sep=",") # Input reference data
Data2 <- read.table("Data2.csv", header=T, sep=",") # Input test data
pc <- prcomp(Data1, scale=TRUE) # Make the model of Principal Component Analysis
pc1 <- predict(pc, Data1)[,1:3] # Apply model for reference data
pc2 <- predict(pc, Data2)[,1:3] # Apply model for test data
write.csv(pc1, file = "pc1.csv") # Output to csv file
write.csv(pc2, file = "pc2.csv") # Output to csv file
NEXT  Model of Abnormal but not Outlier
Model of Abnormal but not Outlier
