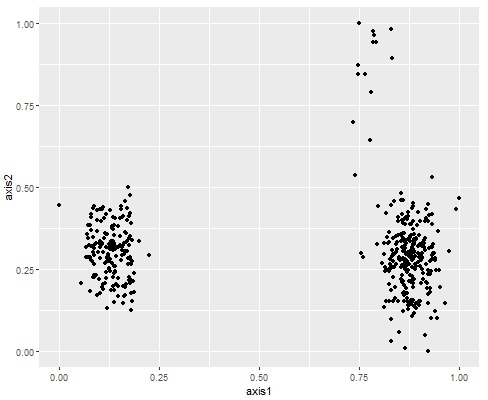
If input data is above, ouput of One-Class SVM is below.
The method classify the input data into "Inside" and "Outside".
One-Class SVM is one of the Support Vector Machine (SVM). But it is used in the different way.
If input data is above, ouput of One-Class SVM is below.
The method classify the input data into "Inside" and "Outside".
General SVM uses Y (label data). But One-Class SVM does not use Y.
Input data has three parts. Output is made wether the point is near the each center or not.
The example is the success case of One-Class SVM.
In the real analysis, we need to change parameters.
If the change is bad, example is below.
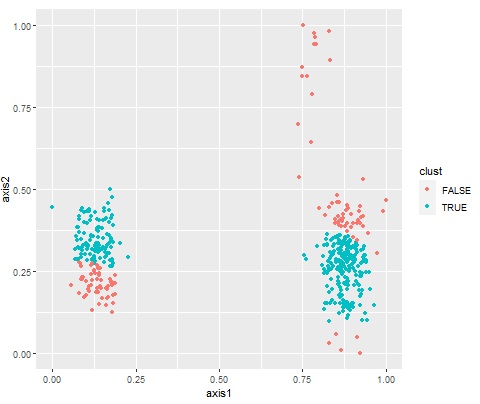
or example, if you know that it is safe near the center of each of the three masses and you need to be vigilant when you are away from those positions, there is data with unknown classification and it corresponds to "outside". If so, you know that you are in a situation to watch out for.
Using this property, it can be used as a method of anomaly detection .
In the R-EDA1 , the above k-Means method is used as a method for grouping data that has been dimensionally compressed and converted into two-dimensional data.
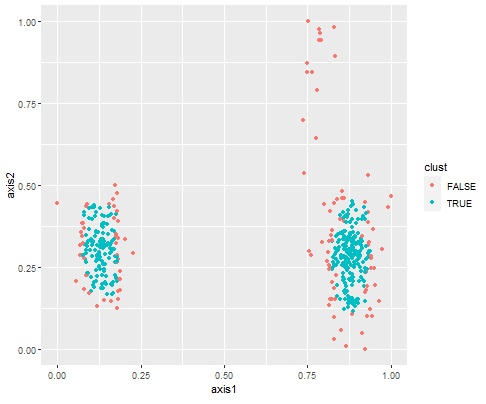
One-Class SVM is also included in this software for this purpose. In general cluster analysis, data chunks are grouped, but with One-Class SVM, the data is grouped inside or outside the chunk, so you can make groups that cannot be done in general cluster analysis.
R-EDA1 can be used in two ways: abnormality judgment and grouping.
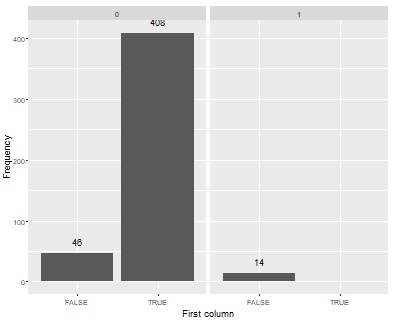
If you follow from the top menu and go to One_Class_SVM_All_Varaiables, you can judge the abnormality by One-Class SVM. In the output bar graph, the data with 0 label (unit space), which is the training data, is on the left side, and the data with 1 label (signal space) is on the right side. As a feature of this method, it is as expected that the number of FALSEs on the 0 side does not become 0. If TRUE appears on the 1st side, it means that it is not well identified.
You can choose from 8 types of kernel functions. Also, in the training data, the parameter au for adjusting the ratio of TRUE and FALSE can be changed.
Also, if you select One_Class_SVM_Selected_Varaiables, you can get the result of calculating all 8 types of kernel functions and all combinations when the features are 1 to 3.

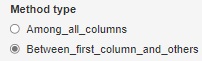


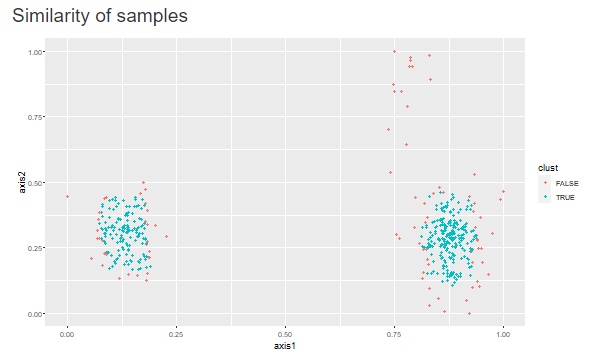
If you follow from the top menu and go to One_class_SVM_Clustering, you can group by One-Class SVM. "Dimension Reduction" is "MDS" in this example, but it can also be "tSNE". However, in any case, it is necessary to check "Add clustering methods".
The types of features and the point that nu can be adjusted are the same as above.

NEXT  MT method
MT method
