
First step of Text Mining is From Sentences to Words . Word cloud is the graph to use in this step.
From the frequency data of the words, word cloud is made like below.
In word cloud, the size of the word means the size of frequency. Positions in the graph do not have any menings. It is the difference from Scatter Plot of Words .
If same data is used for
Bar Plot
.
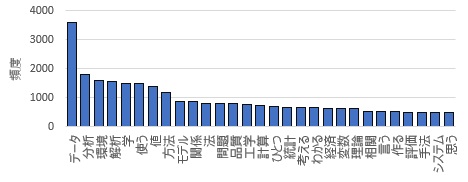
Strongness of bar plot is that it tells us the frequency values. Weakness is that it is difficult to draw information of many words.
Example of R is in the page, Text mining by R.

