 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
形態素解析 をして、テキストを単語に分解した後にできる最初の分析が、単語の出現回数(頻度)の分析です。 ワードクラウドはこの分析に使うグラフです。
形態素解析 をすると、 リンク先のサンプルファイル のようなデータを作ることができます。 1列目の「Term」が単語(形態素)で、2列目の「Freq」が出現回数です。 ちなみに、このデータは、このサイト全体を形態素解析したものです。
このデータをワードクラウドでグラフにすると、こんな感じです。

ワードクラウドでは、出現回数が多いほど、単語の字が大きくなっています。 言葉の散布図 のグラフとは違って、グラフの中の位置には意味がありません。 そのため、単語同士の近さには意味がありません。
字の大きさだけが、意味のあるグラフです。 色は、字の大きさで決まっています。 色分けしないと、かなり見づらいです。
※ サンプルファイルはcsvファイルですが、 Windowsでリンクをクリックすると、「TextData.xls」のファイルとしてダウンロードされることがあります。 そして、そのままこのファイルをExcelで開くと、おかしなデータになります。 ダウンロードした後で、「TextData.csv」というcsvファイルに直してから使ってください。
同じデータについて、出現回数の多いものの
棒グラフ
は、こんな感じです。
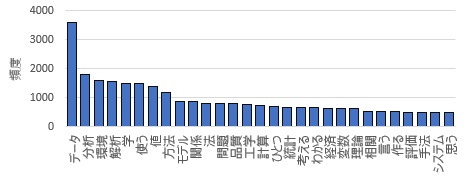
棒グラフでは、具体的な回数がわかるのは良いのですが、ひとつのグラフの中で、上位から数十個くらいしか示せません。
筆者の経験の範囲ですが、 そのテキストの分野に詳しい人が、 テキストマイニング に期待することは、テキストの要約や、見逃していたポイントの発見になっていることが、よくあります。
こうした期待を持っている方には、単語の出現回数の分析は、常識でしかなく、あまり意味がありません。
ワードクラウドは、「ワードクラウドでこんなことを発見しました!」というレポートで使われることがあります。 そのテキストの分野に詳しくない人にとっては、単語の出現回数の分析は、とても意味のあることになって来ます。
Rの実施例は、 Rによるテキストマイニング にあります。
順路
 次は
テキストマイニングのソフト
次は
テキストマイニングのソフト
