 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
クラスター分析 の一般的な使い方は、 サンプルの類似度の分析 ですが、一部の方法については、「 外れ値 」というグループ(クラスター)を作ることができます。
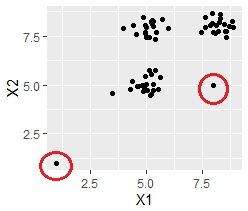
例えば、下の図のように、3つのグループの他に、外れ値が2つあり、この2つを、3つのグループとは別のグループとして取り出したい場合です。
外れ値のモデル のページに、外れ値の判定をする時のデータの使い方として、判定したいデータと参照したいデータを混ぜる方法と、混ぜない方法を説明しています。
判定したいデータと参照したいデータを混ぜる方法として、 階層型の方法とDBSCANを使うことができます。
k-means法、X-means法、混合分布については、「どのグループにも属さないようだ」ということがわかるものがないため、 外れ値の出方によっては、使える場面がありますが、使いにくいです。
例えば、上の例のデータのデンドログラムは下のようになります。
61番と62番のデータが、浮いた感じになっていますので、これを外れ値と考えることができます。
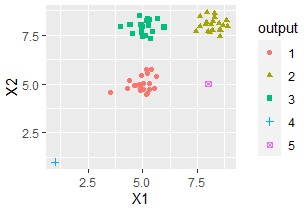
3つの大きなグループの他に、外れ値が2つあることから、合計で5つのグループになると考えて、k=5として、グループを求めると、
狙い通りに外れ値のグループができました。

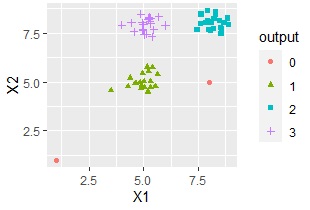
DBSCANやHDBSCANの場合、外れ値は、グループ0というグループに分類されます。
クラスター分析以外の外れたサンプルの探索の手法も含め、手法の違いは、 外れたサンプルの探索 のページにあります。
順路
 次は
アイソレーションフォレスト
次は
アイソレーションフォレスト
