 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
主成分分析 のRによる実施例です。
特にこのページは、 広義の数量化Ⅲ類 と、このサイトで呼んでいる方法の実施例になります。
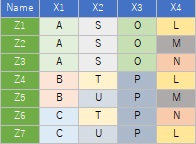
サンプルのデータは下記を使っています。「Name」の列はなくても動きます。
library(fastDummies)# ライブラリを読み込み
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
DataName <- Data$Name # Nameの列を別名で保管する
Data$Name <- NULL # データからNameの列を消して、Xの列だけにする
Data_dmy <- dummy_cols(Data,remove_first_dummy = FALSE,remove_selected_columns = TRUE)# ダミー変換
pca_model <- prcomp(Data_dmy, scale=TRUE) # 主成分分析
summary(pca_model) # 「Cumulative Proportion」が累積寄与率。
手順は、 Rによる変数の類似度の主成分分析 と同じですが、ダミー変換で、ひとつの変数がひとつのカテゴリに対応するようになっているので、 カテゴリの類似度の分析をしていることになります。
pca_data1 <- as.data.frame(pca_model$x) # 主成分得点を得る
pca_dataA <- transform(pc1 ,name = DataName)# サンプル名を追加
pca_dataA$Index <-row.names(Data) # Indexという名前の列を作り、中身は行番号にする
library(ggplot2) # パッケージの読み込み
library(plotly) # パッケージの読み込み
ggplotly(ggplot(pca_dataA, aes(x=PC1, y=PC2,label=name)) + geom_text())# 第1主成分と第2主成分で言葉の散布図
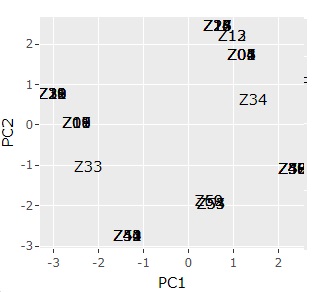
基本的に Rによるサンプルの類似度の主成分分析 です。 ただし、質的変数の場合、「まったく同じ値のサンプル(距離がゼロの組合せ)」が含まれることが多く、そうなると多次元尺度構成法でエラーになります。 そこで、下記では、エラーが起きないUMAPを使っています。
library(MASS)# ライブラリを読み込み
pca_data11 <- pca_data1
row.names(pca_data11) <- DataName
Data11_dist <- dist(pca_data11)# サンプル間の距離を計算
#sn <- sammon(Data11_dist) # 多次元尺度構成法
#output <- sn$points# 得られた2次元データの抽出
library(Rcpp)
library(umap)
ump_out <- umap(as.matrix(Data11_dist),n_neighbors=10) # UMAP n_neighborsは、大き過ぎでも、小さ過ぎでもエラーが出る。
output <- ump_out$layout
Data2 <- as.data.frame(cbind(output, pca_data11)) # 元データと多次元尺度構成法の結果を合わせる。
ggplotly(ggplot(Data2, aes(x=Data2[,1], y=Data2[,2],label=row.names(pca_data11))) + geom_text()) # 言葉の散布図

pca_data2 <- sweep(pca_model$rotation, MARGIN=2, pca_model$sdev, FUN="*") # 因子負荷量を計算
pca_dataB <- transform(pca_data2,nameCol=rownames(pca_data2))# 言葉の散布図
ggplotly(ggplot(pca_dataB, aes(x=PC1, y=PC2,label=nameCol)) + geom_text())# 言葉の散布図
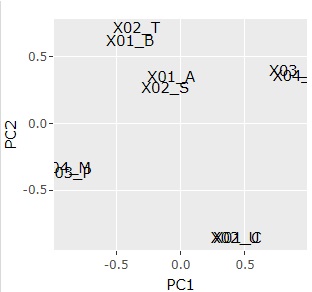
基本的に Rによる変数の類似度の主成分分析 です。 質的変数の場合は、まったく同じということは起こりにくく、 UMAPは、n_neighborsの設定によっては、近くにないはずの組合せが近くになることがあるため、多次元尺度構成法を使っています。
library(MASS)# ライブラリを読み込み
Data11_dist <- dist(pca_data2)# サンプル間の距離を計算
sn <- sammon(Data11_dist) # 多次元尺度構成法
output <- sn$points# 得られた2次元データの抽出
library(Rcpp)
library(umap)
#ump_out <- umap(as.matrix(Data11_dist),n_neighbors=3) # UMAP n_neighborsは、大き過ぎでも、小さ過ぎでもエラーが出る。
#output <- ump_out$layout
Data2 <- as.data.frame(cbind(output, pca_data2)) # 元データと多次元尺度構成法の結果を合わせる。
ggplotly(ggplot(Data2, aes(x=Data2[,1], y=Data2[,2],label=row.names(pca_data2))) + geom_text()) # 言葉の散布図

