 R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
R偵傛傞僨乕僞暘愅
崿崌暘晍MT朄 偼丄 僋儔僗僞乕奜偺梊應偺暘愅 偺堦庬偱偡丅 MT朄 偺墳梡偲丄 僋儔僗僞乕暘愅偵傛傞梊應 偺墳梡偺丄俀偮偺摿挜偑偁傝傑偡丅
堦斒揑側MT朄偼丄 R偵傛傞MT朄 偺儁乕僕偑偁傝傑偡丅
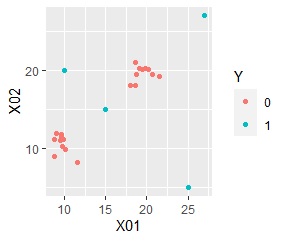
偙偺儁乕僕偺僐乕僪偼丄擖椡僨乕僞偵乽Y乿偲偄偆柤慜偺曄悢偑擖偭偰偄傞偙偲傪憐掕偟偰偄傑偡丅
乽Y乿偺曄悢偼丄乽0乿偲乽1乿偺俀偮偺悢抣偑擖偭偰偄傞偙偲傪憐掕偟偰偄傑偡丅 乽0乿偺僒儞僾儖偼丄扨埵嬻娫偱偁傞偙偲傪憐掕偟偰偄傑偡丅 乽0乿偺僒儞僾儖偩偗偱儌僨儖偑嶌傜傟傑偡丅
乽1乿偺僒儞僾儖偼怣崋嬻娫偱偡丅 扨埵嬻娫偺僨乕僞偵懳偟偰丄堎忢側偺偐傪尒偨偄僨乕僞偵側傝傑偡丅
Y埲奜偺曄悢偼丄柤慜偵寛傑傝偼偁傝傑偣傫丅
寁嶼寢壥偼僌儔僼偵側傞傛偆偵偟傑偟偨偑丄掕検揑側寢壥偲偟偰丄岆敾暿偵側傞僒儞僾儖悢偑傢偐傞傛偆偵傕偟偰傒傑偟偨丅 嵟屻偵弌偰偔傞悢抣偑偦傟偱偡丅
崿崌暘晍MT朄
偼丄懡師尦惓婯暘晍偑暋悢偁傞僨乕僞偑丄扨埵嬻娫偵側偭偰偄傞帪偺曽朄偱偡丅
僋儔僗僞乕暘愅
偱僌儖乕僾偵暘偗偰偐傜丄偦傟偧傟偵懳偟偰MD傪寁嶼偟偰丄奺僒儞僾儖偼MD偺嵟彫抣乮堦斣嬤偄僌儖乕僾偲偺MD乯傪弌椡偟傑偡丅
library(ggplot2) # 儔僀僽儔儕傪撉傒崬傒
library(mclust) # 儔僀僽儔儕傪撉傒崬傒
setwd("C:/Rtest") # 嶌嬈梡僨傿儗僋僩儕傪曄峏
Data <- read.csv("Data.csv", header=T) # 僨乕僞傪撉傒崬傒
Data1 <- Data# 幙揑曄悢偑偁傞応崌偵偙偺峴傪嵎偟懼偊
Data2 <- subset(Data1, Data1$Y == 0)# Y偑0偺僒儞僾儖偺僨乕僞傪暿偵嶌傞
Data2$Y <- NULL # Y偺楍傪徚偡
YData <- Data1$Y# Y偺楍傪暿偵偟偰偍偔
Data4<- as.data.frame(YData)
Data1$Y <- NULL # Y偺楍傪徚偡
k <- ncol(Data2) # 曄悢偺悢傪寁嶼
kNumber <- 2 #僋儔僗僞乕偺悢傪巜掕
mc <- Mclust(Data2,kNumber) # 崿崌暘晍偱暘椶
output <- mc$classification # 暘椶寢壥偺拪弌
Data3 <- cbind(Data2, output)丂 # 嵟弶偺僨乕僞僙僢僩偵僌儖乕僾暘偗偺寢壥傪晅偗傞
for (i2 in 1:kNumber) { #
Data101 <- subset(Data3, Data3$output == i2)# output偑1偺僒儞僾儖偺僨乕僞傪暿偵嶌傞
Data101$output <- NULL # output偺楍傪徚偡
n1 <- nrow(Data101) # output偑1偺僒儞僾儖偺僒儞僾儖悢傪寁嶼
Ave1 <- colMeans(Data101) # output偑1偺僒儞僾儖偺奺曄悢偺暯嬒抣傪寁嶼
Var1 <- var(Data101)*(n1 - 1)/n1 # output偑1偺僒儞僾儖偺嫟暘嶶峴楍傪寁嶼
MD <- mahalanobis(Data1, Ave1, Var1)/k # MD乮偺俀忔乯傪寁嶼
Data4 <- cbind(Data4,MD)
colnames(Data4)[i2+1]<-i2
} #
Data5 <- Data4
Data4$YData <- NULL # Y偺楍傪徚偡
MinMD<- apply(Data4, 1, min)
MinMD<- as.data.frame(MinMD)
Data5 <- cbind(Data5,MinMD)
Data5$YData <- factor(Data5$YData)#丂Y偺楍傪暥帤宆偵偡傞
ggplot(Data5, aes(x=YData, y=MinMD)) + geom_jitter(size=1, position=position_jitter(0.1))# 堦師尦僕僞乕嶶晍恾傪昤偔
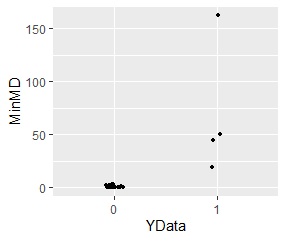
俀偮偺僌儖乕僾偺偳偪傜偐傜傕棧傟偨僒儞僾儖偼丄MD偑崅偔側偭偰偄傑偡丅
摨巙幮戝妛丂嬥柧揘愭惗偺儁乕僕
R偲敾暿暘愅
https://www1.doshisha.ac.jp/~mjin/R/Chap_18/18.html
儅僴儔僲價僗嫍棧傪巊偆敾暿暘愅偲偟偰丄崿崌暘晍MT朄偲傎傏摨偠曽朄偑徯夘偝傟偰偄傑偡丅
偙偺儁乕僕偺僐乕僪傪嶌傞帪偵嶲峫偵偝偣偰偄偨偩偒傑偟偨丅
