 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
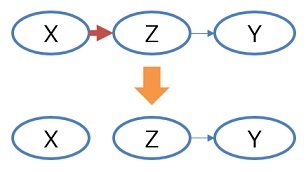
d分離
をした時の、X、Y、Zの関係があるとします。
傾向スコアは、あるXの時の、Zの確率のことです。 例えば、「Xが50の時に、Zが処理ありになる確率は、0.3」と言ったものになります。
XとZが、いずれも0と1の、二値なら、傾向スコアは、例えば、Xが0で、Zが0の時の割合、というようにして求まります。
Xが量的変数で、Zが二値の場合は、 ロジスティック回帰分析 を使うのが一般的のようです。
傾向スコアの使い方としては、 マッチング法 のようにサンプリングに使う場合と、 反事実を考慮して使う場合の2つが代表的のようです。
マッチング法 は、 計量経済学 の文献で、よく紹介されています。
傾向スコアが近くて、処置あり・処置なしの関係がある2つのサンプルに対して、「事実・反事実の関係」とみなして 事実と反事実の分析をする方法です。
d分離 を明示的に行う方法として使われます。 具体的には、平均処置効果の計算で補正値として使われます。
この補正は、さらに一歩進んで、反事実のデータがある場合の考慮も傾向スコアを使う方法があります。 この応用は、 反実仮想機械学習 につながっています。
「つくりながら学ぶ! Pythonによる因果分析 因果推論・因果探索の実践入門」 小川雄太郎 著 マイナビ出版 2020
調整化公式の導き方、また、そこからの傾向スコアの導き方が、コンパクトにまとまっています。
傾向スコアを使う方法も、いろいろ紹介しています。
逆確率重み付け法(IPTW):処置あり・なしのそれぞれの項について、傾向スコアで補正
Doubly Robust法(DR法):IPTWの改良版。平均処置効果を計算する時に、処置あり・なしのサンプルのデータだけでなく、傾向スコアを使って、反実仮想も想定して計算する方法
X-Lerner:T-Lernerで2つのモデルの重み付けに傾向スコアを使う。第3の変数の影響が弱まるように重み付けする。
Doubly Robust Lerning(DR-Lerner):DR法の応用。反実仮想の推定に傾向スコアを使う。
順路
 次は
検証したい原因系の変数が量的変数の因果推論
次は
検証したい原因系の変数が量的変数の因果推論
