 僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
僩僢僾儁乕僕 |
傂偲偮忋偺儁乕僕 |
栚師儁乕僕 |
偙偺僒僀僩偵偮偄偰 |
ENGLISH
暯嬒抣偺嵎偺専掕 偺儁乕僕偵偁傝傑偡偑丄暯嬒抣偺嵎偺専掕偺p抣偼丄暯嬒抣偺嵎偺桳柍偩偗傪挷傋偨偄帪偺広搙偵側偭偰偄傑偡丅
偲偙傠偱丄昅幰偺宱尡偺斖埻偱偼丄暯嬒抣偺嵎偺専掕傪偡傞幚柋忋偺応柺偱丄乽暯嬒抣偺嵎偺桳柍偩偗傪挷傋偨偄乿偲偄偆偙偲偼巚偄摉偨傝傑偣傫丅 抦傝偨偄偺偼丄乽暘晍偑偢傟偰偄傞偲尵偊傞偺偐丠乿丄乽偢傟偼丄偳偺偔傜偄偐丠乿偲偄偆偙偲側偺偱偡偑丄 偦傟傪抦傞偨傔偺庤抜偲偟偰丄暯嬒抣偺嵎偺専掕傪巊偭偰偄傞偺偑幚忬偱偡丅
偦偙偱昅幰偑抦傝偨偄偙偲傪挷傋傞偨傔偺捈愙揑側庤抜偲偟偰峫埬偟偨偺偑丄偙偺儁乕僕偱乽暯嬒抣偺嵎偺専掕偺o抣乿偲昅幰偑柤晅偗偨曽朄偵側傝傑偡丅 乮悽偺拞偵偼丄婛偵摨偠曽朄偑偁傞偐傕偟傟側偄偱偡偑丄昅幰偺抦傞尷傝偱偼側偝偦偆偱偡丅 傕偟偁傟偽丄柤慜偼偦偪傜偵崌傢偣傞偮傕傝偱偡丅乯
僐乕僄儞偺d偲丄o抣偺娭學偑壓偺恾偱偡丅
偄偢傟傕僐乕僄儞偺d偑彫偝偗傟偽侾偵嬤晅偒丄戝偒偗傟偽侽偵嬤晅偔惈幙傪帩偭偰偄傞偙偲偑傢偐傝傑偡丅
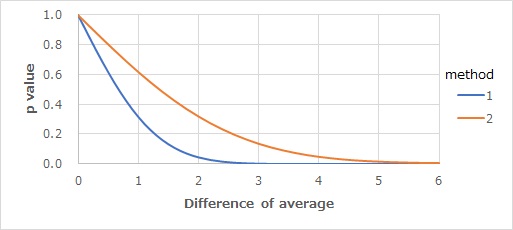
僐乕僄儞偺d偑侾偔傜偄偺帪偵丄俁偮偺曽朄偺堘偄偑戝偒偔側傝傑偡丅
壓偺椺偼丄俁偮偺椺偵偮偄偰丄o抣傪寁嶼偟偰傒偨傕偺偱偡丅 偦傟偧傟偺僌儔僼偺忋偵偁傞悢帤偑o抣偱偡丅
俁偮偺椺偼丄X2偺暯嬒抣偩偗偑堘偄傑偡丅
偦傟埲奜偼摨偠偱偡丅
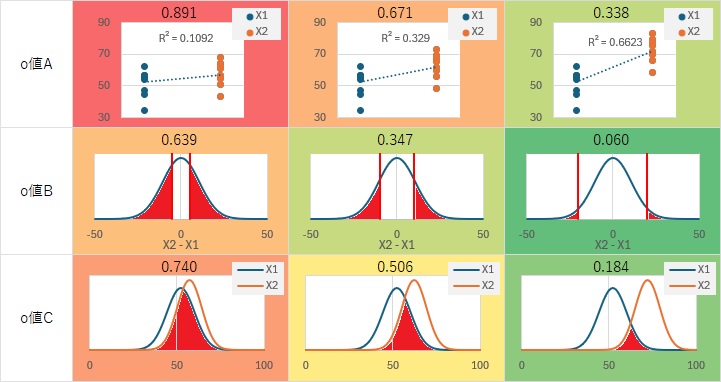
憡娭學悢偺専掕偺o抣A 偲婎杮揑偵摨偠偱偡丅 愢柧曄悢傪侽偲侾偺俀抣偵偡傞偙偲偱丄憡娭學悢傪媮傔傑偡丅
=1- R1^2
o抣偺怣棅嬫娫乮忋懁乯偱偡丅 憡娭學悢偺怣棅嬫娫 傪巊偄傑偡丅
=1-( ( EXP(LN( (1+R1)/(1-R1) ) -2*1.96/SQRT(n1-3) ) -1) / ( EXP(LN( (1+R1)/(1-R1) ) -2*1.96/SQRT(n1-3) ) +1) )^2
暯嬒抣偺嵎偑俀偱丄俀偮偺暘晍偺昗弨曃嵎偑偄偢傟傕1偺応崌丄o抣B偼丄壓偺僌儔僼偺愒偄晹暘偺柺愊偺斾棪偱偡丅
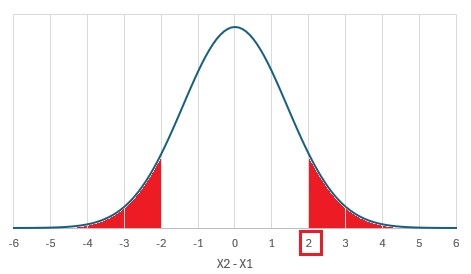
偙偺僌儔僼偼丄X2-X1偺昗弨曃嵎偐傜丄X2-X1偺暘晍傪媮傔傞偙偲偱嶌偭偰偄傑偡丅
X2-X1偺昗弨曃嵎偼丄
暯嬒張抲岠壥偲屄暿張抲岠壥偺娭學
偺儁乕僕偵偁傞峫偊曽傪巊偆偲丄
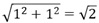
偱偡丅
D1丄N1丄N2丄S1丄S2偺僙儖偵偦傟偧傟抣傪彂偄偰偍偒丄擟堄偺僙儖偵壓婰偺娭悢傪僐僺乕偡傞偺偑丄堦斣娙扨側巊偄曽偱偡丅
EXCEL偺応崌丄椺偊偽丄嵎偑d1偺応崌丄壓偺幃偱o抣偑媮傑傝傑偡丅
=(1 - NORM.DIST(d1/sqrt((s1^2 + s2^2)),0,1,TRUE)) *2
sqrt((s1^2 + s2^2))
偺晹暘偼丄
暯嬒張抲岠壥偲屄暿張抲岠壥偺娭學
偺峫偊曽傪巊偭偰偄傑偡丅
o抣偺怣棅嬫娫偼丄 p抣偺怣棅嬫娫 偲摨條偵丄岠壥検偺怣棅嬫娫偺忋懁偲壓懁偺抣傪丄o抣偺寁嶼幃偵擖傟偰寁嶼偡傟偽椙偝偦偆偱偡丅
壓婰偼丄忋懁偺媮傔曽偱偡偑丄壓懁偱傕摨條偱偡丅
EXCEL偺応崌丄椺偊偽丄嵎偑俀偺応崌丄壓偺幃偱o抣偺怣棅嬫娫乮忋懁乯偑媮傑傝傑偡丅
=(1 - NORM.DIST(2 / sqrt(s1^2 + s2^2) - 1.96*sqrt(1/n1 + 1/n2),0,1,TRUE)) *2
偪側傒偵丄o抣偺怣棅嬫娫偺忋懁偵偼丄岠壥検偺怣棅嬫娫偺壓懁傪巊偆偺偱丄乽 - 1.96乿偲偄偆晹暘偵側偭偰偄傑偡丅
暯嬒抣偺嵎偺専掕偺o抣C偼丄幚嵺偺僨乕僞偵懳偟偰丄摑寁妛揑側暘晍偱嬤帡偟偰寁嶼偡傞揰傗丄o抣傪寁嶼偡傞揰偼丄摑寁妛揑側 専掕 偺曽朄偲摨偠偱偡丅
傑偨丄敾暿偺惓岆偺妱崌偱敾掕偡傞揰偼丄 敾暿暘愅 偺傛偆側 儔儀儖暘椶 偺曽朄偲摨偠偱偡丅
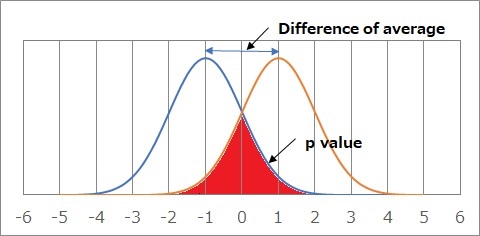
昗弨曃嵎偑侽偺惓婯暘晍偑俀偮偁偭偰丄暯嬒抣偑俀偢傟偰偄傞応崌偑忋偺恾偱偡丅
惓婯暘晍偺嵎偺専掕俀偱偼丄愒偔偟偨晹暘偺柺愊傪丄p抣偲峫偊傑偡丅
暯嬒抣偺嵎偺専掕偺o抣A偱偼丄幚嵺偺僨乕僞偱嶌偭偨僸僗僩僌儔儉偵偮偄偰丄俀偮偺暘晍偺廳側傝崌偭偰偄傞晹暘傪寁嶼偡傞偺偱偼側偔丄 幚嵺偺僨乕僞偐傜嶌偭偨妋棪枾搙娭悢偱暘晍傪嬤帡偟偰寁嶼偟傑偡丅
偙偆偡傞偙偲偱丄俀偮偺暘晍偺僒儞僾儖悢偑戝偒偔堘偭偰偄偰傕塭嬁偑側偄偱偡偟丄僨乕僞偑彮側偄帪偵婲偒傞僨乕僞偺慹偝偺塭嬁傪彫偝偔偱偒傑偡丅
嵎偑d1偱丄昗弨曃嵎偑s偺応崌丄壓偺幃偱o抣偑媮傑傝傑偡丅
=(1 - NORM.DIST(d1 / (2 * s), 0, 1, TRUE))*2
椺偊偽丄忋偺僌儔僼偺傛偆偵丄嵎偑俀偱丄昗弨曃嵎偑侾偺応崌丄壓偺幃偱o抣偑媮傑傝傑偡丅
=(1 - NORM.DIST(1,0,1,TRUE))*2
摍暘嶶偱偼側偄応崌偼丄昗弨曃嵎偺暯嬒抣傪寁嶼偵僐乕僄儞偺d偱巊傢傟偰偄傞曽朄傪巊偆偙偲偵偟偰丄埲壓偱椙偄偺偱偼側偄偐偲峫偊偰偄傑偡丅
EXCEL偺応崌丄椺偊偽丄嵎偑d1偱丄昗弨曃嵎偑s1偲s2偺応崌丄壓偺幃偱o抣偑媮傑傝傑偡丅
=(1 - NORM.DIST(d1 / (2 * sqrt((n1*s1^2 + n2*s2^2) / (n1+n2))), 0, 1, TRUE))*2
乽摑寁専掕庤朄偺夵妚...偦偺3: 岠壥検, 怣棅嬫娫乿丂惣堜弤丂2016
僐乕僄儞偺d偲丄偦偺怣棅嬫娫偺徯夘偑偁傝傑偡丅
https://bcl.sci.yamaguchi-u.ac.jp/~jun/post/160605-effectsize/
弴楬
 師偼
21悽婭偺丄暯嬒抣偺専掕
師偼
21悽婭偺丄暯嬒抣偺専掕
