 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて | ENGLISH
「このカテゴリと関係が強いカテゴリは?」という分析は、 決定木 でもできますが、 アソシエーション分析 は、決定木よりも直接的に、この分析ができるようになっています。
ただ、アソシエーション分析は、すべてのカテゴリの組合せを網羅的に調べるため、非常に時間がかかります。 これが原因で、フリーズすることもあります。
1変数中心型アソシエーション分析は、この弱点を解消するために、考案したものです。 先行研究があれば、名前は合わせますが、さしあたってなさそうなので、この名前にしています。
いわゆるマーケット・バスケット分析では、有望な組合せを見つけたいので、すべての組合せを調べ切る必要があります。
一方、決定木に変わる分析方法として使う時は、注目しているカテゴリがあって、それを中心にして、他のカテゴリを調べられれば、一番知りたいことは知ることができます。 1変数中心型は、この点に着目して、注目しているカテゴリとの組合せだけを、調べます。 こうすることで、計算量を大幅に減らすことができます。
1変数中心型のひとつの利点は、上記のように計算量です。 他にもあります。 分析したいカテゴリが決まっている時の分析に適している点があります。 特に、異常の原因分析のように、サンプルの少ないカテゴリを分析したい時に適しています。
例えば、異常の原因分析では、ある変数の中で異常を表すカテゴリと、他のカテゴリとの関係が調べたいです。 アソシエーション分析は、そのカテゴリと関係のないカテゴリの組合せも大量に抽出するため、注目したい組合せが埋もれがちです。
また、アソシエーション分析に「支持度」という指標がありますが、異常の原因分析では、大多数のサンプルは正常で、異常のサンプルは、ごく少数です。 そのため、異常のカテゴリが抽出されにくく、抽出されたとしても、埋もれやすいです。
1変数中心型にすると、これらの問題を避けることができます。
下記に、RやR-EDA1で行う方法を書きましたが、いずれも注目したい変数は、1と0の2値データを前提にしました。 例えば異常の分析なら、異常のカテゴリを1にして、正常を0にします。
コードとしては、注目したい変数が、「合格・不合格」のような2値の質的変数や、多値の質的変数でも作ることができますが、 質的変数にすると、注目したいカテゴリが明示的にならないため、1と0を前提にしています。
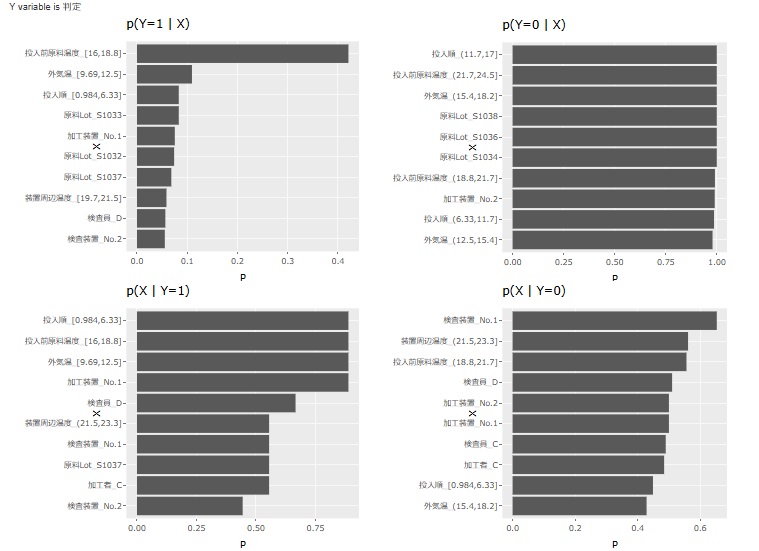
1変数中心型を使いたい場面では、データ全体についての発生確率を見ることにあまり意味がないので、確信度を見ることにしています。
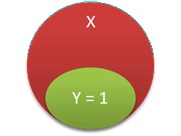
Xになっているサンプルの中の、Y=1になっているサンプルの割合、「Y=1ならば、X」の確率
原因分析の場合、この確率が高いという事は、Xの条件が起きた時に、高確率でY=1になっていることになります。
因果関係は、「XならばY=1」となりますが、包含関係は「Y=1ならばX」となります。
「ならば」の前後が逆になる、ややこしいパターンです。
Y=1になっているサンプルの中の、Xになっているサンプルの割合、「Xならば、Y=1」の確率
原因分析の場合、この確率が高いからと言って、必ずしもXが原因とは言えないことに注意が必要です。 正常のサンプルでも、高い可能性があります。
異常のサンプルで、この確率が高く、正常のサンプルで、この確率が低ければ、Xが原因の可能性が出て来ます。
この指標は、分母がY=1のサンプル数で共通になります。 そのため、Y=1に限定して、 支持度 の分析をしていることにもなります。
Xになっているサンプルの中の、Y=0になっているサンプルの割合、「Y=0ならば、X」の確率
Y=1の場合に注目しがちですが、Y=1で起きていることが、Y=0でも起きているのなら、Y=1の原因とは考えられないです。 そのため、Y=0の場合も確認が必要です。
XY=0になっているサンプルの中の、Xになっているサンプルの割合、「Xならば、Y=0」の確率
この指標は、分母がY=0のサンプル数で共通になります。 そのため、Y=0に限定して、 支持度 の分析をしていることにもなります。
1変数中心型の場合は、ネットワークグラフにする必要がないです。
そこで、棒グラフにするのが、一番良いようです。
ひとつのカテゴリについて、できるだけ多くの組合せを調べることができます。
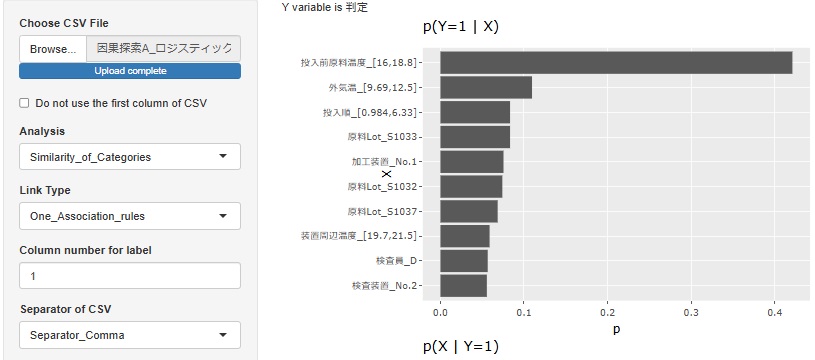
Rによる実施例は、 Rによる1変数中心型アソシエーション分析 にあります。
上の例は、
R-EDA1を使っています。
順路
 次は
コレスポンデンス分析
次は
コレスポンデンス分析
