 トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
トップページ |
ひとつ上のページ |
目次ページ |
このサイトについて |
ENGLISH
P値の問題点と、その対策については、 P値の改良案・代案・補強案、 統計的な検定と、統計教育の歴史、 21世紀の検定 といったページで説明しています。
一方で、筆者の知っている範囲にはなりますが、「検定ではP値で判断する」という認識は、今でも検定の一般的なユーザの中では多数派の認識です。 今までに何十年もかけて、ようやく一部の分野で変わった状況なので、一般的なユーザの認識まで変わっていくのは、あと数十年〜百年くらいかかるのではないかと思います。
そのため、「検定ではP値で判断する」が常識のようになっている組織の中で、組織が間違った方向に進まないように、現実的な対応が必要になります。
学会や会社などによっては、手順がある程度決まっていることがあるので、直近の先例を参考にするのが得策と思います。 ガイドラインがある分野もあります。
以下は、そのような先例やガイドラインがない場合の、手順や注意点です。
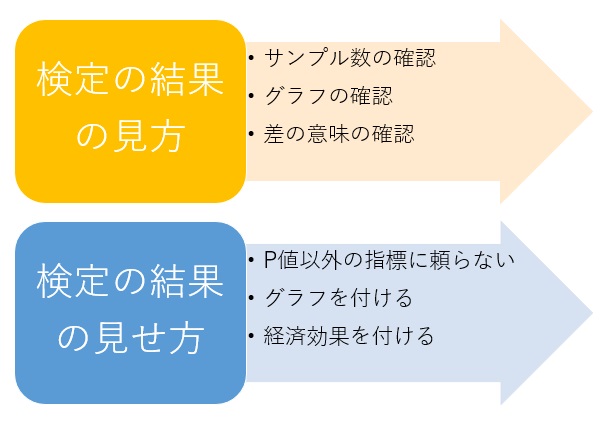
「検定ではP値で判断する」が常識のようになっている組織では、調査結果や実験結果として、P値が示されることになりますが、その時の対応の仕方です。
意思決定をする立場になった場合の、注意点です。
P値が0.05以上の場合は、従来通りに、「差はない」と判断しても、あまり問題は起きません。
ただし、例えば、P値が0.05以上で「差はない」となったとしても、実際は対策の効果があるのに、データの精度が低いので、データでは差が見えないこともあります。
P値が0.05以下の場合、従来通りに「差はある」と判断する前に、サンプル数を確認します。
サンプル数が5個くらいまでで、「P値が0.05以下」という結果になっているのなら、従来通りに、「差はある」と判断しても、あまり問題は起きません。 理由は、 スモールデータの検定の効果量 にあります。
サンプル数が10個程度よりも大きい場合は、ヒストグラムなどのグラフを使って、分布の違いを確認します。
P値や効果量などの数字だけで、結論を出していないかを確認します。
グラフがあるのか、グラフでは、データがどのように見えているのかを確認します。
グラフでデータの出方を見ます。 平均値付近ではないデータの位置が、特にポイントです。
検定では、データの測定の仕方や、データの精度などとは無関係に結果が出ます。 どのようにして得られたデータなのかは、確認が必要です。 例えば、対策には効果がなくても、データを測定した日が違うために、「差がある」という検定の結果になることもあります。
差の意味で検定を補強 することは、統計的な数値による混乱を避けるのに良いです。
21世紀の検定 では、P値の他に、「P値の信頼区間」、 「効果量」、 「効果量の信頼区間」、 「寄与率、寄与率の信頼区間」も指標として挙げています。
これらの指標を計算してみると、結果を考察する時に参考になるので、個人的な分析にはおすすめです。 しかし、組織への報告会などで、これらの指標を使った発表をすると、混乱の原因になるかもしれないので、あまりおすすめしません。
P値が0.05以上の場合は、スモールデータかどうかに関わらず、仮説を主張しない方が良いです。 ギリギリ0.05以下の場合も、気を付けた方が良いです。
心理学関係では、 効果量 を説明している本が、筆者の知っているだけでも5冊くらいあります。
分野によっては、効果量の理解者が増えて来ているので、P値以外に効果量も示した方が良いことがあります。
ただし、理解者がいない場に、効果量を登場させると、それが新たな混乱を起こして、本来やるべきことから離れてしまうかもしれないので、自分の組織の状況次第です。
検定を使うような状況では、グラフでは明確に分かれないという不安要素を、統計学の力で定量的に補強する目的のことがあります。
グラフを出すと、明確に分かれていないので、「この程度の違いは、違いではない」と言われやすくなるリスクがあります。
ただ、現実には、そのあたりの不確実性も踏まえて、対策を打つ方が、リスク管理がしやすいです。
検定の結果だけでは、「どのくらい事業に貢献するのか」、「どのくらいの確からしさのある対策なのか」といったことがわからず、確信や納得がしにくいので、意思決定がしにくい場合があります。 そのような時は、「効果」や「差」は、お金に換算すると、会社の中でのデータ分析では、意思決定がしやすくなります。
例えば、「年間人件費の3人分」、「毎月の売上の10%」といった数字と比べられるようにします。
順路
 次は
多重性の問題
次は
多重性の問題
