 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
ランダムフォレスト のRによる実施例です。
平均化による 変数の重要度の分析は、 ランダムフォレストの使い方として、よく知られています。
このコードの前に、ライブラリ「randomForst」のインストールが必要です。
データは、Yと20個のXがあるとします。90行分あります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
library(randomForest) # ライブラリを読み込み
Data <- read.csv("Data.csv", header=T, stringsAsFactors=TRUE) # データを読み込み
treeModel <- randomForest(Y ~ ., data = Data, ntree = 10)# 木を10個作る。省略すると500個
varImpPlot(treeModel) # 変数の重要度のグラフを作る

予測値の求め方は、他の手法と同じで 予測のためのソフトの使い方 にあります。
randomForestのライブラリは、 ランダムフォレスト を使って、重要な変数を探したり、予測をするのに便利に作られています。 上記のように、平均化による変数の重要度の分析の機能もあります。
しかし、それらの計算の途中で作られる個々の木(フォレスト:森)が、どのように作られたかというのは、 それらしい情報は見れるのですが、出力する機能はないようです。
そこで、筆者は、木の構造を出力するためのコードを作ってみました。
randomForestのコードではなく、rpart、CAHID、C5.0のそれぞれをベースにしています。 一般的なランダムフォレストは2進木なので、一般的なランダムフォレストの計算途中の木に近い結果が出るのは、rpartをベースにしたものになります。 N進木 のものが欲しかったので、CHAIDベースとC5.0ベースのランダムフォレストも作ってみました。
ポイントになるのは10回分のデータセットの作り方です。 このコードでは、自分で調整できるのが便利です。
このコードの前に、ライブラリ「partykit」のインストールが必要です。
データは、Yと20個のXがあるとします。90行分あります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
library(rpart) # ライブラリを読み込み
library(partykit) # ライブラリを読み込み
Data <- read.csv("Data.csv", header=T) # データを読み込み
ncolMax <- ncol(Data) # データの列数を求める
nrowMax <- nrow(Data) # データの行数を求める
DataY <- Data$Y # Yの列を別名で保管する
Data$Y <- NULL # データからYの列を消して、Xの列だけにする
for (i in 1:9) { # ループの始まり。「9」でランダムサンプリングを9回実行することを表す
DataX <- Data[,runif (floor(sqrt(ncolMax)), max=ncolMax)]# ランダムに列数の平方根の数の列を選択する
Data1 <- transform(DataX, Y = DataY) # Yと選択したXで新しいデータセットを作る
Data2 <- Data1[runif (floor(sqrt(nrowMax)), ,max=nrowMax), ]# ランダムに行数の平方根の数の行を選択する
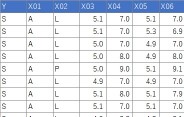
treeModel <- rpart(Y ~ ., data = Data2, minsplit = 3)# rpartを実行
jpeg(paste("plot",i,".jpg"), width = 300, height = 300) # 描画デバイスを開く
plot(as.party(treeModel)) # グラフにする。繰り返した回数分のグラフファイルができる。
dev.off() # 描画デバイスを閉じる
} # ループの終わり
このコードを実行すると、作業用ディレクトリに結果の画像ファイルが木の数だけ作成されます。
狙い通りに、枝が3つ以上になる木もできました。
このコードの前に、ライブラリ「partykit」と「C50」のインストールが必要です。
データは、上記と同じです。
setwd("C:/Rtest") # 作業用ディレクトリを変更
library(C50) # ライブラリを読み込み
library(partykit) # ライブラリを読み込み
Data <- read.csv("Data.csv", header=T, stringsAsFactors=TRUE) # データを読み込み
ncolMax <- ncol(Data) # データの列数を求める
nrowMax <- nrow(Data) # データの行数を求める
if (class(Data$Y) == "numeric") { # 条件分岐の始まり
Data$Y <- droplevels(cut(Data$Y, breaks = 5,include.lowest = TRUE))# 5分割する場合。量的データは、質的データに変換する。
} # if文の処理の終わり
DataY <- Data$Y # Yの列を別名で保管する
for (i in 1:ncolMax) { # ループの始まり。データの列数を数えて同じ回数繰り返す
if (class(Data[,i]) == "logical") { # 条件分岐の始まり
Data[,i] <- as.factor(Data[,i])# logical型の列は、factor型に変換する。
} # if文の処理の終わり
} # ループの終わり
Data$Y <- NULL # データからYの列を消して、Xの列だけにする
for (i in 1:9) { # ループの始まり。「9」でランダムサンプリングを9回実行することを表す
DataX <- Data[,runif (floor(sqrt(ncolMax)), max=ncolMax)]# ランダムに列数の平方根の数の列を選択する
Data1 <- transform(DataX, Y = DataY) # Yと選択したXで新しいデータセットを作る
Data2 <- Data1[runif (floor(sqrt(nrowMax)), ,max=nrowMax), ]# ランダムに行数の平方根の数の行を選択する
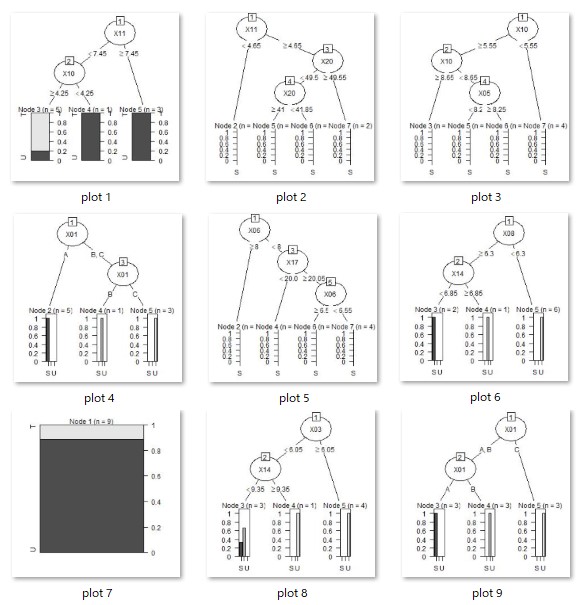
treeModel <- C5.0(Y ~ ., data = Data2)# C5.0を実行
jpeg(paste("plot",i,".jpg"), width = 300, height = 300) # 描画デバイスを開く
plot(as.party(treeModel)) # グラフにする。繰り返した回数分のグラフファイルができる。
dev.off() # 描画デバイスを閉じる
} # ループの終わり
このコードを実行すると、作業用ディレクトリに結果の画像ファイルが木の数だけ作成されます。
狙い通りに、枝が3つ以上になる木もできました。
量的データも3分岐以上になる N進木 にしたい場合は、CHAIDを使っても良いと思います。
下のコードの特徴ですが、CHAIDであることの他に、 アンサンブル学習 のページに書いている「列のバギング」になっています。 つまり、サンプリングは列だけで、行はしていません。
C5.0ベースのものと比べると、計算時間が長いです。
このコードの前に、ライブラリ「CHAID」のインストールが必要です。
setwd("C:/Rtest") # 作業用ディレクトリを変更
library(CHAID) # ライブラリを読み込み
Data <- read.csv("Data.csv", header=T, stringsAsFactors=TRUE) # データを読み込み
ncolMax <- ncol(Data) # データの列数を求める
nrowMax <- nrow(Data) # データの行数を求める
for (i in 1:ncolMax) { # ループの始まり。データの列数を数えて同じ回数繰り返す
if (class(Data[,i]) == "numeric") { # 条件分岐の始まり
Data[,i] <- droplevels(cut(Data[,i], breaks = 5,include.lowest = TRUE))# 5分割する場合。量的データは、質的データに変換する。
} # if文の処理の終わり
} # ループの終わり
DataY <- Data$Y # Yの列を別名で保管する
Data$Y <- NULL # データからYの列を消して、Xの列だけにする
for (i in 1:9) { # ループの始まり。「9」でランダムサンプリングを9回実行することを表す
DataX <- Data[,runif (floor(sqrt(ncolMax)), max=ncolMax)]# ランダムに列数の平方根の数の列を選択する
Data1 <- transform(DataX, Y = DataY) # Yと選択したXで新しいデータセットを作る
#Data2 <- Data1[runif (floor(sqrt(nrowMax)), ,max=nrowMax), ]# ランダムに行数の平方根の数の行を選択する
Data2 <- Data1# 行はサンプリングしない
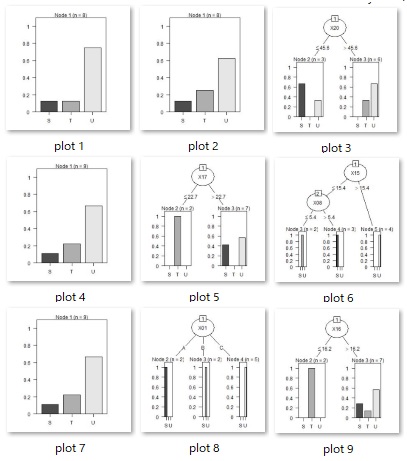
treeModel <- chaid(Y ~ ., data = Data2)# C5.0を実行
jpeg(paste("plot",i,".jpg"), width = 600, height = 300) # 描画デバイスを開く
plot(treeModel) # グラフにする。繰り返した回数分のグラフファイルができる。
dev.off() # 描画デバイスを閉じる
} # ループの終わり
RのCHAIDのパラメータ
https://rdrr.io/rforge/CHAID/man/chaid.html
CHAIDのインストール
CHAIDは、一般的なRのパッケージとは違って、CRANにはありません。このページのファイルをダウンロードして手動で読み込むか、
R-forgeから読み込むように設定を変える必要があります。
https://r-forge.r-project.org/R/?group_id=343
同志社大学 金明哲先生のページ
Rと集団学習
https://www1.doshisha.ac.jp/~mjin/R/Chap_32/32.html
Rでバギングして、個々の木を見る
https://toukeier.hatenablog.com/entry/2018/09/10/214253#%E3%83%90%E3%82%AE%E3%83%B3%E3%82%B0%E3%81%AE%E4%BE%8B
このページの例とは違うコードが載っていますが、
ランダムフォレスト用のデータセットを作るためのヒントは、これを参考にさせていただきました。
http://tips-r.blogspot.com/2014/06/r1.html
Pythonで、木をたくさん作る過程を動画にする話があります。
https://watlab-blog.com/2020/01/06/random-forest-animation/
