Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
なお、決定木には、 機械学習 の手法のひとつとして 予測 に使う使い方もありますが、 過学習 になったり、粗過ぎたりで、ちょうど良い感じにしにくいので、この使い方をしないです。
Rで決定木を使う場合、ライブラリーがいろいろあり、一長一短です。
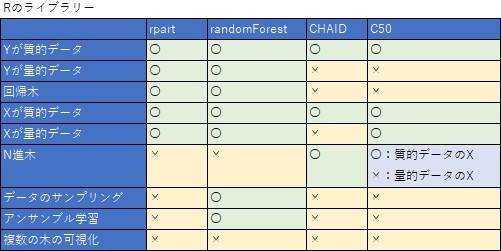
実務の中で使うため、
短所の部分については、このサイトのサンプルコードでは、改善させるようにしています。
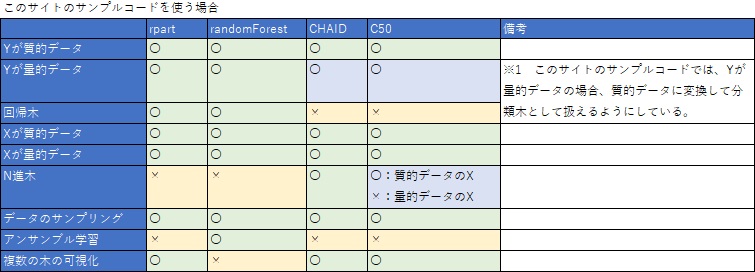
rpartはよくできていて、Yの種類を自動的に判断して、質的データなら分類木を実行し、量的データなら回帰木を実行します。 また、Xは質的データと量的データが混ざっていても使えます。
CHAIDやC5.0で、 特に何もケアせずに、rpartのようにして実行すると、「データが論理型や文字列型」の場合にエラーが出てしまいます。 CHAIDやC5.0では、このエラーを回避するための前処理があるため、rpartに比べるとコードが長くなります。
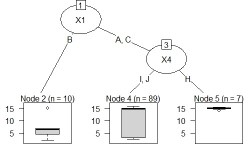
分類木と回帰木 と入門的な使い方の例です。
Rの使用例は下記になります。 (下記は、コピーペーストで、そのまま使えます。 この例では、Cドライブの「Rtest」というフォルダに、 「Data.csv」という名前でデータが入っている事を想定しています。 このコードの前に、ライブラリ「partykit」のインストールが必要です。
データは、Yと20個のXがあるとします。90行分あります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
library(partykit) # ライブラリを読み込み
library(rpart) # ライブラリを読み込み
Data <- read.csv("Data.csv", header=T) # データを読み込み
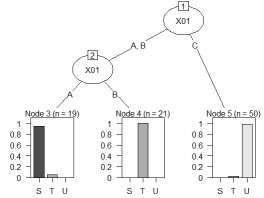
treeModel <- rpart(Y ~ ., data = Data)# rpartを実行
plot(as.party(treeModel)) # グラフにする。
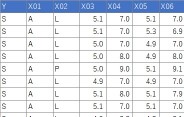
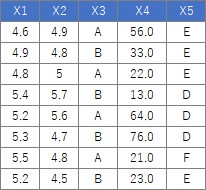
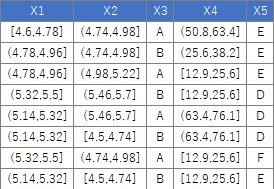
下のようなデータについて、「量的データの列は、質的データにまとめて変換」という処理は、下記でできます。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
for (i in 1:ncol(Data)) { # ループの始まり。データの列数を数えて同じ回数繰り返す
if (class(Data[,i]) == "numeric") { # 条件分岐の始まり
Data[,i] <- droplevels(cut(Data[,i], breaks = 5,include.lowest = TRUE))# 5分割する場合。量的データは、質的データに変換する。
} # if文の処理の終わり
} # ループの終わり
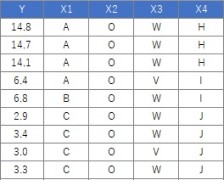
データは、Yと4つのXがあるとします。106行分あります。
コードは、上記とまったく同じで良いです。
Yが量的データなら、回帰木として処理されます。