 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
検定 は、「違いがあると言えるのか?」という事について、定量的な分析ができます。
平均値の差の検定 は、検定の中でも基本的なものになります。 データは、2列あって、1列目と2列目を比べることを想定しています。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
t.test(x=Data$X1,y=Data$X2,var.equal=T,paired=F) # スチューデントのt検定
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
t.test(x=Data$X1,y=Data$X2,var.equal=F,paired=F) # ウェルチのt検定
library("exactRankTests")
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
wilcox.exact(x=Data$X1,y=Data$X2,paired=F) # ウィルコクソンの順位和検定
発生数の差の検定 です。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
Data1 <- Data[,1]
Data2 <- Data[,2]
Data1 <- Data1[!is.na(Data1)]
Data2 <- Data2[!is.na(Data2)]
mean1<-mean(Data1)
mean2<-mean(Data2)
n1<-length(Data1)
n2<-length(Data2)
mean3<-sum(Data1,Data2)/(n1+n2)
Poisson_z <-abs(mean1-mean2) / sqrt(mean3*(1/n1 + 1/n2))# z値
pval <- 1 - pnorm(Poisson_z, mean = 0, sd =1)# z検定
pval # p値
effect_size <- abs(mean1-mean2) / sqrt(mean3) # 効果量
effect_size # 効果量
2つ以上の母平均の差の検定は、「 分散分析 」と呼ばれているものがあります。
データは、1列目は「X」という列名でカテゴリ、2列目は「Y」という列名で数値が入っていることを想定しています。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
summary(aov(Y~X,data=Data)) # 一元配置分散分析
データは、1列目、2列目は「X1」、「X2」という列名で水準名、3列目は「Y」という列名で数値が入っていることを想定しています。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
summary(aov(Y~X1+X2,data=Data)) # 二元配置分散分析(交互作用項なし)
交互作用 も評価する場合は、「+」の所が、「*」になります。
交互作用項を入れる場合は、繰り返しデータが必要になります。 繰り返しデータとは、2つの因子のそれぞれの水準の組み合わせについて、複数回分のデータがあることを指します。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
summary(aov(Y~X1*X2,data=Data)) # 二元配置分散分析(交互作用項あり)
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
kruskal.test(x=list(Data$X1,Data$X2))# クラスカル-ウォリス検定
対応のありの平均値の差の検定 です。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
t.test(x=Data$X1,y=Data$X2,paired=T) # 対応のある平均値の差の検定
library("exactRankTests")
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
wilcox.exact(x=Data$X1,y=Data$X2,paired=T) # ウィルコクソンの順位和検定
library(DescTools)
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
SignTest(x=Data$X1,y=Data$X2) # 符号検定
データは、1列目、2列目は「X1」、「X2」という列名でカテゴリ、3列目は「Y」という列名で数値が入っていることを想定しています。 「X2」が対応を表す文字列になります。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
summary(aov(Y~X1+X2,data=Data)) # 対応のある一元配置分散分析
ばらつきの違いの検定 です。
データは、2列あって、「X1」、「X2」という列名が1行目にあって、その下に数値が入っていることを想定しています。)
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
var.test(x=Data$X1,y=Data$X2) # 2つの母分散の比の検定
データは、1列目は「X」という列名でカテゴリ、2列目は「Y」という列名で数値が入っていることを想定しています。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
bartlett.test(formula=Data$Y~Data$X) # バートレット検定
Rでできるムッド検定を、素直に検索すると、「stats」というパッケージにある「mood.test」を紹介している記事ばかり出て来るのですが、 「stats」は、CRANの中にないようでした。 代わりのものを探したところ、「coin」の中に、「mood_test」というものがあり、これで代用できました。
coinには、mood_testの他に、taha_test、klotz_test、ansari_testというものもあり、これらもムッド検定と同様に、ばらつきの違いの検定として分類されています。
library("coin")
library(tidyr)
setwd("C:/Rtest")
Data <- read.csv("Data.csv", header=T)
Data_long <- tidyr::gather(Data, key="Xs", value = Val) # 2列のデータを、1列にまとめる
Data_long$Xs <-as.factor(Data_long$Xs)
mood_test(Val ~ Xs, data = Data_long)# ムッド検定
「1/10」と「4/20」の差の検定の場合
prop.test(c(1,4),c(10,20))# 比率の差の検定
カイ二乗検定を使った 独立性の検定 です。
setwd("C:/Rtest") # 作業用ディレクトリを変更
Data <- read.csv("Data.csv", header=T) # データを読み込み
chisq.test(Data)# カイ二乗検定
マクマネー検定 です。
a b
c d
の行列の場合、下記は、
c(a, c, b, d)とすると同じになります。
mcnemar.test(matrix(c(1, 4, 10, 20), 2, 2)) # マクマネー検定
setwd("C:/Rtest")
Data <- read.csv("Data.csv", header=T)
ks.test(x=Data[,1],y=Data[,2]) # コルモゴロフ-スミルノフ検定
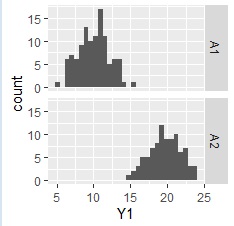
データは、「C1」という列名でカテゴリ、「Y1」という列名で数値が入っていることを想定しています。
ggplot(Data, aes(x=Y1)) + geom_histogram() + facet_grid(C1~.)# 層別ヒストグラムを描く
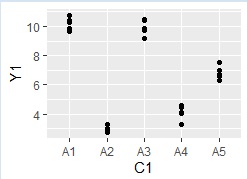
ggplot(Data, aes(x=C1, y=Y1)) + geom_point() # 一次元散布図を描く
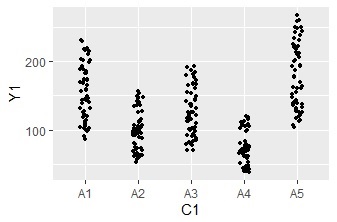
プロットの大きさはsize、横方向の散らばり具合はposition=position_jitterの数字で調節できます。
ggplot(Data, aes(x=C1, y=Y1)) + geom_jitter(size=1, position=position_jitter(0.1))# 一次元ジター散布図を描く
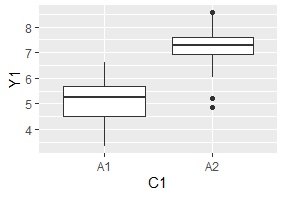
ggplot(Data, aes(x=C1, y=Y1)) + geom_boxplot() # 箱ひげ図を描く
ggplot(Data, aes(x=Y1)) + geom_histogram() + facet_grid(C1+C2~.)# 2段層別ヒストグラムを描く
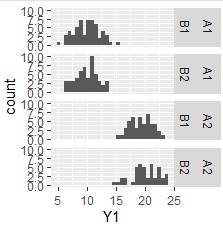
ggplot(Data, aes(x=C1, y=Y1)) + geom_jitter(size=1, position=position_jitter(0.1)) +facet_grid(.~C2)# 一次元散布図(二元配置)を描く

「Package ‘coin’」 2023
coinのマニュアルです。
https://cran.r-project.org/web/packages/coin/coin.pdf
